文章目录
前言
本节就来看看Netty提供给用户开箱即用的解码器:LengthFieldBasedFrameDecoder。
在看之前尽量保证有一定的ByteBuf基础,如必须知道readerIndex和,writerIndex等,可以参考我前面的博客记录【ByteBuf简介】。
如果对解码器的大致流程还存在疑问,建议回去看看【ByteToMessageDecoder】,本文不会再提及整体流程,核心关注解码器的decode方法。
另外LengthFieldBasedFrameDecoder的入门比前面讲到的DelimiterBasedFrameDecoder、LineBasedFrameDecoder等都要难很多,但是作为Netty中比较常用的解码器,我们还是不得不学。
不过当你懂了之后,你会发现还是很简单,只是官方文档的例子太"硬核"了。
Netty Version:4.1.6
实验代码
同样拿Netty的单元测试做例子(我改动了一些),还有代码注释是我自己写的,现在如果无法理解代码也是正常的,相信到最后会豁然开朗的:
LengthFieldBasedFrameDecoderTest.java
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import io.netty.channel.embedded.EmbeddedChannel;
import org.junit.Assert;
import org.junit.Test;
import static io.netty.util.ReferenceCountUtil.releaseLater;
public class LengthFieldBasedFrameDecoderTest {
@Test
public void testDiscardTooLongFrame1() {
ByteBuf buf = Unpooled.buffer();
/*
* | 4 byte|
* +-------+
* | 32 | length = 4 bytes
* +-------+
*/
buf.writeInt(32);
/*
* | 4 bytes| 32bytes |
* +--------+---*---+-----------+----+
* | 32 | 1 | 2 | ... | 32 | length = 36 bytes
* +--------+---+---+-----------+----+
*/
for (int i = 0; i < 32; i++) {
buf.writeByte(i);
}
/*
* | 4 bytes| 32bytes | 4 bytes|
* +--------+---*---+-----------+----+--------+
* | 32 | 1 | 2 | ......... | 32 | 1 | length = 40 bytes
* +--------+---+---+-----------+----+--------+
*/
buf.writeInt(1);
/*
* | 4 bytes| 32bytes | 4 bytes|1 bytes|
* +--------+---*---+-----------+----+--------+-------+
* | 32 | 1 | 2 | ......... | 32 | 1 | a | length = 41 bytes
* +--------+---+---+-----------+----+--------+-------+
*/
buf.writeByte('a');
EmbeddedChannel channel = new EmbeddedChannel(new LengthFieldBasedFrameDecoder(36, 0, 4));
try {
channel.writeInbound(buf);
Assert.fail();
} catch (TooLongFrameException e) {
// expected
}
Assert.assertTrue(channel.finish());
ByteBuf b = channel.readInbound();
int readableBytes = b.readableBytes();
System.out.println(readableBytes);
Assert.assertEquals(5, readableBytes);
// 读取4字节数据
int readInt = b.readInt();
System.out.println(readInt);
Assert.assertEquals(1, readInt);
// 读取1字节数据
byte readByte = b.readByte();
System.out.println((char)readByte);
Assert.assertEquals('a', readByte);
b.release();
Assert.assertNull(channel.readInbound());
channel.finish();
}
实验代码的输出结果如下:
5
1
a
- 至于这几个输出结果是怎么出来的,相信看完这篇博客就能懂了。
跟进源码
LengthFieldBasedFrameDecoder继承关系
先来看看LengthFieldBasedFrameDecoder的继承关系图:
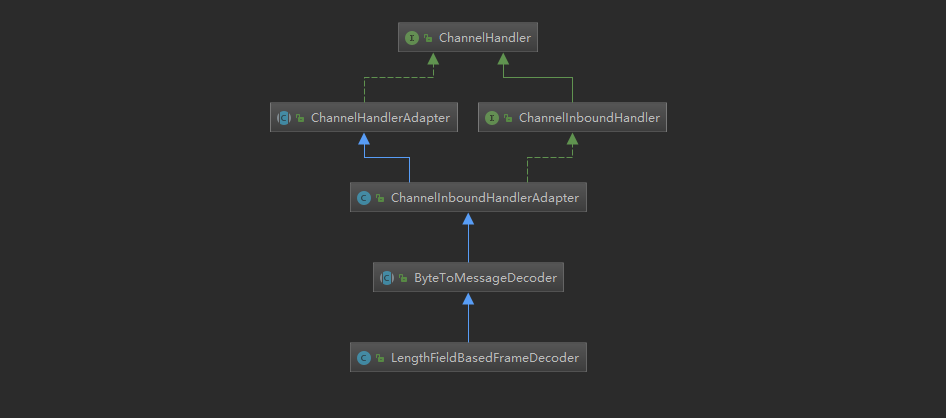
- 关于图中的几个类,我在【inbound和oubound事件区别】提到过。
- ByteToMessageDecoder在【上一节】提到过。
从上面的类图,再结合之前pipeline的学习经历,不难发现,我们其实可以把LengthFieldBasedFrameDecoder当成ChannelHandler,也就是说解码其实是事件传播、处理中的其中一环。用代码表示就是类似下面这个样子:
// 略
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new Base64Decoder());
ch.pipeline().addLast(new DelimiterBasedFrameDecoder());
ch.pipeline().addLast(new FixedLengthFrameDecoder(3));
ch.pipeline().addLast(new LineBasedFrameDecoder(10, false, false));
}
- (上面这段话在上一节已经说过了,直接拿过来用是为了给自己强调一下)
LengthFieldBasedFrameDecoder的属性分析
我之所以说LengthFieldBasedFrameDecoder难,其实就难在理解它的属性,可能我脑子比较蠢,足足花了差不多2个小时才算是初步理解了官方文档中对属性的讲解。
下面就先来看看它的属性,第一次看肯定是非常绝望的:
public class LengthFieldBasedFrameDecoder extends ByteToMessageDecoder {
/** 排序枚举 */
private final ByteOrder byteOrder;
/** 数据包最大长度 */
private final int maxFrameLength;
/** 长度域偏移的字节数 */
private final int lengthFieldOffset;
/** 长度域占用的字节数 */
private final int lengthFieldLength;
/** lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength
* 在构造方法中有这个算式
* */
private final int lengthFieldEndOffset;
/** 修正长度域的值 */
private final int lengthAdjustment;
/** 砍掉数据包开头后指定字节数 */
private final int initialBytesToStrip;
/** 数据包长度大于maxFrameLength时是否抛出异常 */
private final boolean failFast;
/** 是否正处于丢弃模式 */
private boolean discardingTooLongFrame;
/** 丢弃的长度 */
private long tooLongFrameLength;
/** 剩余要丢弃的字节 */
private long bytesToDiscard;
...(非属性代码略)
- 想要完全理解这些属性,可能还需要你自己花上一点时间。我的博客(下文)也不一定能帮你理解这些属性,但还是有一定参考意义的。
下面还是用官方文档的例子来慢慢理解,很长,希望有耐心点看完:
lengthFieldLength
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = 0
initialBytesToStrip = 0 (= do not strip header)
解码前 (14 bytes) 解码后 (14 bytes)
|2 bytes | 12 bytes | |2 bytes | 12 bytes |
+--------+----------------+ +--------+----------------+
| length | Actual Content |----->| Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+
- lengthFieldLength=2表示长度域的值占2字节,然后解码器获取到前两字节的数据为12,这个12就是初始长度域的值。
- 然后解码器就在再往后读取12个字节,跟前2字节一起组成一个数据包(解码前后无变化)。
initialBytesToStrip
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = 0
initialBytesToStrip = 2 (= the length of the Length field)
解码前 (14 bytes) 解码后 (12 bytes)
|2 bytes | 12 bytes | | 12 bytes |
+--------+----------------+ +----------------+
| Length | Actual Content |----->| Actual Content |
| 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
+--------+----------------+ +----------------+
- lengthFieldLength=2表示长度域的值占2字节,然后解码器获取到前2字节的数据为12,这个12就是初始长度域的值。
- 之后,initialBytesToStrip=2告诉解码器:开头的前2个字节不需要读的。于是,编码器就把readerIndex移动到第2个字节处,也就是把原本读到的HDR1域,和长度域丢掉。
- 终于,编码器可以开始读数据了,从开头的第2字节处往后读了12个字节,即由"HELLO, WORLD"组成的数据包。
lengthAdjustment
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = -2 (= the length of the Length field)
initialBytesToStrip = 0 (= do not strip header)
解码前 (14 bytes) 解码后 (14 bytes)
|2 bytes | 12 bytes | |2 bytes | 12 bytes |
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+
- lengthFieldLength=2表示长度域的值占2字节,然后解码器获取到前2字节的数据为14,这个14就是初始长度域的值。
- 如果按照上面的逻辑,那解码器就要往后读取14字节的数据了,可是后面只有12字节啊,这时候lengthAdjustment就派上用场了。
- 要读取的真实字节数=初始长度域值(14)+ lengthAdjustment(-2),然后解码器发现initialBytesToStrip=0,表示不需要丢弃字节,就会往后读"要读取的真实字节数"个字节并和前面读取到的2字节组成数据包。
- 参数意义:当长度域的值表示其它意义时,可以用lengthAdjustment来修正要读取的字节数。
lengthFieldOffset
lengthFieldOffset = 2
lengthFieldLength = 3
lengthAdjustment = 0
initialBytesToStrip = 0 (= do not strip header)
解码前 (17 bytes) 解码后 (17 bytes)
| 2 bytes | 3 bytes | 12 bytes | | 2 bytes | 3 bytes | 12 bytes |
+----------+----------+----------------+ +----------+----------+----------------+
| Header 1 | Length | Actual Content |----->| Header 1 | Length | Actual Content |
| 0xC AFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+
- 这次又有点不一样了,因为lengthFieldOffset=2,这个参数告诉解码器,长度域的值不是从开头的字节读起了,而是开头字节的后2位开始读起,因为开头的2位是别的数据域,不属于长度域。
- 好了,现在解码器就从第3字节开始往后读3字节,成功拿到了长度域的初始值,也就是12。
- 最后,发现lengthAdjustment、initialBytesToStrip都=0,则不需要额外操作,往后读12字节再加上前面读到的5字节组成数据包。
仍然是lengthAdjustment,但这次和之前的有点不一样了
lengthFieldOffset = 0
lengthFieldLength = 3
lengthAdjustment = 2 (= the length of Header 1)
initialBytesToStrip = 0
解码前 (17 bytes) 解码后 (17 bytes)
| 3 bytes | 2 bytes | 12 bytes | | 3 bytes | 2 bytes | 12 bytes |
+----------+----------+----------------+ +----------+----------+----------------+
| Length | Header 1 | Actual Content |----->| Length | Header 1 | Actual Content |
| 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+
- lengthFieldLength=3表示长度域的值占3字节,然后解码器获取到前3字节的数据为12,这个12就是初始长度域的值。
- 但此时解码器发现lengthAdjustment=2,即lengthFieldLength需要修正成14(=12+2),不然只往后读12字节取不到完整的数据了。
- 最后,发现lengthAdjustment、initialBytesToStrip都=0,则不需要额外操作,往后读14字节再加上前面读到的3字节组成数据包。
下面是两个综合案例,可能会再次刷新你在上文"认为这样就是对的"想法,这一点儿也不奇怪:
lengthFieldOffset = 1 (= the length of HDR1)
lengthFieldLength = 2
lengthAdjustment = 1 (= the length of HDR2)
initialBytesToStrip = 3 (= the length of HDR1 + LEN)
解码前 (16 bytes) 解码后 (13 bytes)
|1 bytes|2 bytes |1 bytes| 12 bytes | |1 bytes| 12 bytes |
+-------+--------+-------+----------------+ +-------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x000 C| 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+-------+--------+-------+----------------+ +-------+----------------+
- lengthFieldOffset=1而!=0,这个参数告诉解码器,长度域的值不是从开头的字节读起了,而是开头字节的后1位开始读起,因为开头的1位是别的数据域,不属于长度域。
- 好了,现在解码器就从第2字节开始往后读2字节,成功拿到了长度域的初始值,也就是12。
- 此时解码器还发现lengthAdjustment=1,即lengthFieldLength需要修正成13(=12+1),不然只往后读12字节取不到完整的数据了。
- 之后,initialBytesToStrip=3告诉解码器:开头的前3个字节不需要读的。于是,编码器就把readerIndex移动到第3个字节处,也就是把原本读到的HDR1域,和长度域丢掉。
- 终于,编码器可以开始读数据了,从开头的第3字节处往后读了13个字节,即由HDR2域和"HELLO, WORLD"组成的数据包。
lengthFieldOffset = 1
lengthFieldLength = 2
lengthAdjustment = -3 (= the length of HDR1 + LEN, negative)
initialBytesToStrip = 3
解码前 (16 bytes) 解码后 (13 bytes)
|1 bytes|2 bytes |1 bytes| 12 bytes | |1 bytes| 12 bytes |
+-------+--------+-------+----------------+ +-------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xC A | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+-------+--------+-------+----------------+ +-------+----------------+
- lengthFieldOffset=1而!=0,这个参数告诉解码器,长度域的值不是从开头的字节读起了,而是开头字节的后1位开始读起,因为开头的1位是别的数据域,不属于长度域。
- 好了,现在解码器就从第2字节开始往后读2字节,成功拿到了长度域的初始值,也就是16。
- 此时解码器还发现lengthAdjustment=-3,即lengthFieldLength需要修正成13(=16-3),因为后面之后13字节的数据可读了。
- 之后,initialBytesToStrip=3告诉解码器:开头的前3个字节不需要读的。于是,编码器就把readerIndex移动到第3个字节处,也就是把原本读到的HDR1域,和长度域丢掉。
- 终于,编码器可以开始读数据了,从开头的第3字节处往后读了13个字节,即由HDR2域和"HELLO, WORLD"组成的数据包。
以上分析不会的话建议多看几遍,因为我自己在理解的时候也对着官方文档来来回回滚了好几遍。
decode实现
接下来就是核心的部分了,也就是对ByteToMessageDecoder累加器传过来的数据进行解码。
另外,墙裂建议先理解了上面的提到的属性才看decode实现,不然后果自负:
io.netty.handler.codec.LengthFieldBasedFrameDecoder#decode(io.netty.channel.ChannelHandlerContext, io.netty.buffer.ByteBuf, java.util.List<java.lang.Object>)
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
if (decoded != null) {
// 解码出的对象添加到out中,交给ByteToMessageDecoder传播
out.add(decoded);
}
}
继续跟进decode方法:
io.netty.handler.codec.LengthFieldBasedFrameDecoder#decode(io.netty.channel.ChannelHandlerContext, io.netty.buffer.ByteBuf)
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 丢弃模式下处理
if (discardingTooLongFrame) {
// 剩余要丢弃的字节数
long bytesToDiscard = this.bytesToDiscard;
// 取 可读字节数和剩余丢弃字节数 之中最小的
int localBytesToDiscard = (int) Math.min(bytesToDiscard, in.readableBytes());
// 丢弃
in.skipBytes(localBytesToDiscard);
// 更新剩余要丢弃的字节数
bytesToDiscard -= localBytesToDiscard;
// 保存剩余要丢弃的字节数
this.bytesToDiscard = bytesToDiscard;
// 没必要快速抛出异常
failIfNecessary(false);
}
// 如果可读数据字节数 < 自定义数据包大小,即不完整数据包不完整,不解码
if (in.readableBytes() < lengthFieldEndOffset) {
return null;
}
// Length域偏移后的指针位置
// 结合实验代码最终=0
int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;
// frameLength即长度域的值
// 结合实验代码:从头开始向后读4个字节(lengthFieldLength),frameLength=32。
/*
* | 4 bytes| 32bytes | 4 bytes|1 bytes|
* +--------+---*---+-----------+----+--------+-------+
* | 32 | 1 | 2 | ......... | 32 | 1 | a | length = 41 bytes
* +--------+---+---+-----------+----+--------+-------+
*/
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);
if (frameLength < 0) {
in.skipBytes(lengthFieldEndOffset);
throw new CorruptedFrameException(
"negative pre-adjustment length field: " + frameLength);
}
// 总共要读取的字节数 = 长度域的点值 + 修正量 + (Length本身占用字节 + Length偏移量)
// 结合实验代码,frameLength = 36(=32+4)
// 另外,提醒下此处还未计算要抛弃的字节数(initialBytesToStrip)
frameLength += lengthAdjustment + lengthFieldEndOffset;
// 要读取的长度小于应该要读取的长度(一个数据包长度),有问题,抛出异常
if (frameLength < lengthFieldEndOffset) {
in.skipBytes(lengthFieldEndOffset);
throw new CorruptedFrameException(
"Adjusted frame length (" + frameLength + ") is less " +
"than lengthFieldEndOffset: " + lengthFieldEndOffset);
}
// 要读取的长度 > 最大长度
if (frameLength > maxFrameLength) {
// 剩余要丢弃的字节数
long discard = frameLength - in.readableBytes();
// 总共丢弃的字节数
tooLongFrameLength = frameLength;
if (discard < 0) {
// buffer contains more bytes then the frameLength so we can discard all now
in.skipBytes((int) frameLength);
} else {
// 开启丢弃模式
discardingTooLongFrame = true;
// 记录剩余要丢弃的字节数
bytesToDiscard = discard;
// 丢弃当前所有可读字节并移动read指针
in.skipBytes(in.readableBytes());
}
// 快速异常
failIfNecessary(true);
return null;
}
// never overflows because it's less than maxFrameLength
int frameLengthInt = (int) frameLength;
// 如果可读取的字节数 < 打算读取的字节数,说明字节流还不足以拼装成一个数据包
if (in.readableBytes() < frameLengthInt) {
return null;
}
// 如果要扔掉的字节数 > 要读取的字节数,说明不正常,抛出异常
if (initialBytesToStrip > frameLengthInt) {
in.skipBytes(frameLengthInt);
throw new CorruptedFrameException(
"Adjusted frame length (" + frameLength + ") is less " +
"than initialBytesToStrip: " + initialBytesToStrip);
}
// 指针向后移动initialBytesToStrip个字节
// 结合实验代码,我们是没有设置丢弃字节的,所以readerIndex原地不动。
in.skipBytes(initialBytesToStrip);
// extract frame
int readerIndex = in.readerIndex();
// 最终实际需要读取的字节数 = 原本打算要读取的字节数 - 要抛弃的字节数
// 结合实验代码:initialBytesToStrip=0,所以actualFrameLength = 36
int actualFrameLength = frameLengthInt - initialBytesToStrip;
// 根据已经移动到“被抛弃字节后”的read指针、要读取的长度,正式开始读取数据并封装成数据包(解码)
ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);
// 将read指针移动到已经读取的数据后
in.readerIndex(readerIndex + actualFrameLength);
// 返回数据包
return frame;
}
结合实验代码用流程“图”表示就是以下的样子:
/**
* 解码前
*/
| 4 bytes| 32bytes | 4 bytes|1 bytes|
+--------+---*---+-----------+----+--------+-------+
| 32 | 1 | 2 | ......... | 32 | 1 | a | length = 41 bytes
+--------+---+---+-----------+----+--------+-------+
↑ ↑
| |
readerIndex writerIndex
|||
|||
|||
|||||||||||
|||||||
|||
|
/**
* 解码后
*/
| 4 bytes| 32bytes | 4 bytes|1 bytes|
+--------+---*---+-----------+----+--------+-------+
| 32 | 1 | 2 | ......... | 32 | 1 | a | length = 41 bytes
+--------+---+---+-----------+----+--------+-------+
↑ ↑
| |
readerIndex writerIndex
根据以上流程图的最终结果,相信实验代码的输出结果应该秒懂了:
5 // b.readableBytes():获取累加器中剩余可读字节数,即writerIndex-readerIndex
1 // b.readInt():读取readerIndex后4位字节的数据(readerIndex也要移动4字节),后4字节的值就是1。
读完后变成以下“图”:
| 4 bytes| 32bytes | 4 bytes|1 bytes|
+--------+---*---+-----------+----+--------+-------+
| 32 | 1 | 2 | ......... | 32 | 1 | a | length = 41 bytes
+--------+---+---+-----------+----+--------+-------+
↑ ↑
| |
readerIndex |
writerIndex
a // b.readByte():读取readerIndex后1位字节的数据(readerIndex也要移动1字节),后1字节的值就是字母a。
读完之后变成以下“图”:
| 4 bytes| 32bytes | 4 bytes|1 bytes|
+--------+---*---+-----------+----+--------+-------+
| 32 | 1 | 2 | ......... | 32 | 1 | a | length = 41 bytes
+--------+---+---+-----------+----+--------+-------+
↑
|
writerIndex=readerIndex
好了,LengthFieldBasedFrameDecoder的decode方法以及成功调试的案例就讲到这里了,如果你对一些bad case、丢弃模式等感兴趣,请拿Netty的单元测试自己调试摸索吧。不过在此之前,任然建议你先完全理解LengthFieldBasedFrameDecoder的属性含义,否则没法看懂代码。