目录
前言
在开篇之前,下面先讲一下我学习ByteBuf相关知识的感受。
本以为有了前段时间学习channel、pipeline、事件传播等源码经历,如今学习ByteBuf应该是会越来越轻松才对,结果我发现自己还是太天真了。因为ByteBuf分配内存的源码中,充斥着各种各样的位运算,虽然能从里面学到不少技巧,但由于我日常开发很少用到位运算(可能是我水平不够吧),所以第一次看ByteBuf计算相关源码时是一脸懵逼的。
那么这节就来看看ByteBuf的基础结构以及常见分类,在之后的章节如果忘记就回来看。
Netty Version:4.1.6
ByteBuf结构、核心api
数据结构
首先通过官方给出的结构图直观感受下ByteBuf的内存结构:
+-------------------+------------------+------------------+
| discardable bytes | readable bytes | writable bytes |
| | (CONTENT) | |
+-------------------+------------------+------------------+
| | | |
0 <= readerIndex <= writerIndex <= capacity
接下来解释一下这些名词:
- discardable bytes:已经被读取过的数据,一般情况下可以理解为无效区域。
- readable bytes:未读取数据,readable bytes数据区的数据是满的,都是等待读取的数据。
- writable bytes:空闲区域,可以往这块区域写数据。
- capacity:表示当前内存容量。
- readerIndex:读数据起点指针,当需要读数据时,就以当前指针为起点往后读取数据。
- writerIndex:写数据起点指针,当需要写数据时,就以当前指针为起点往后写数据。
下面通过一些核心api直观感受下代码操作是什么样的:
随机读取数据
ByteBuf buffer = ...;
for (int i = 0; i < buffer.capacity(); i ++) {
byte b = buffer.getByte(i);
System.out.println((char) b);
}
顺序读取1字节数据
ByteBuf buffer = ...;
while (buffer.isReadable()) {
System.out.println(buffer.readByte());
}
顺序读取4字节数据
ByteBuf buffer = ...;
while (buffer.isReadable()) {
System.out.println(buffer.readInt());
}
- readBoolean()就是读2字节,其它以此类推。
顺序写数据
ByteBuf buffer = ...;
while (buffer.maxWritableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
discardReadBytes()废弃数据
废弃数据后
+------------------+--------------------------------------+
| readable bytes | writable bytes (got more space) |
+------------------+--------------------------------------+
| | |
readerIndex (0) <= writerIndex (decreased) <= capacity
clear()清除缓冲区索引
清除后
+---------------------------------------------------------+
| writable bytes (got more space) |
+---------------------------------------------------------+
| |
0 = readerIndex = writerIndex <= capacity
mark和reset方法
读和写操作都有对应的mark方法和reset方法都,其作用就类似于“指针回滚”,mark方法用于标记读/写之前的指针位置,而reset方法则是将当前指针回滚到mark标记处。
下面看看这两接口长啥样:
ByteBuf分类
先通过类图看看关系:
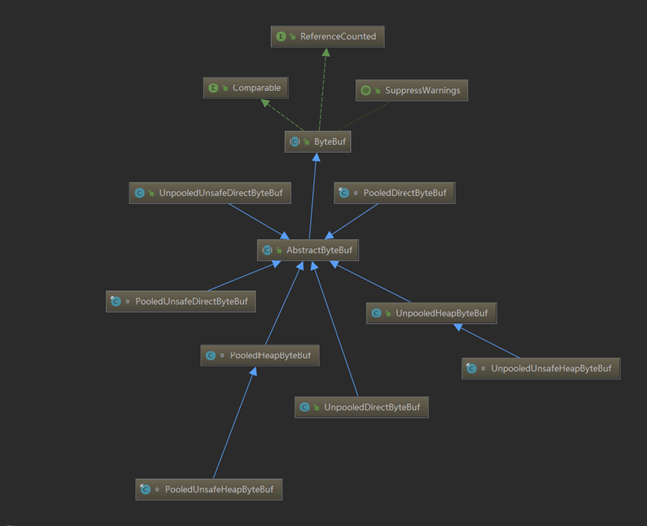
于是可以分为以下6类:
- Unpooled:非池化,每次申请内存都是新的一次申请。
- Pooled:池化,每次申请内存都是从jdk已经分配好的内存池中取。
- direct:堆外内存,即系统直接内存,不受jvm管控。
- heap:堆内存,就是指jvm的堆内存。
- 非unsafe:通过jdk的api间接操作底层内存。
- unsafe:指调用native方法底层直接操作内存(一般不会由用户调用)。
- 除此之外,还有组合ByteBuf等类型,由于不是特别重要就不仔细介绍了,有兴趣的自己去补充一下吧~
关于直接内存,我在网上找到比较简单&全面的概括:
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区
域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错出现。JDK1.4 中新加入的 NIO(New Input/Output) 类,引入了一种基于通
道(Channel) 与缓存区(Buffer) 的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆之间来回复制数据。本机直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
更详细的就得要自己补充了。
safe和unsafe区别
下面就以读取数据为例,简单看下safe和unsafea的api的区别。
首先找到io.netty.buffer.AbstractByteBuf#readByte方法:
@Override
public byte readByte() {
checkReadableBytes0(1);
int i = readerIndex;
byte b = _getByte(i);
readerIndex = i + 1;
return b;
}
跟进_getByte方法,这是一个抽象方法:
protected abstract byte _getByte(int index);
先选择一个unsafe实现:
io.netty.buffer.UnpooledUnsafeHeapByteBuf#_getByte
@Override
protected byte _getByte(int index) {
return UnsafeByteBufUtil.getByte(array, index);
}
跟进getByte方法:
io.netty.buffer.UnsafeByteBufUtil#getByte(byte[], int)
static byte getByte(byte[] array, int index) {
return PlatformDependent.getByte(array, index);
}
持续跟进getByte方法(中间过程略),来到如下代码:
io.netty.util.internal.PlatformDependent0#getByte(byte[], int)
static byte getByte(byte[] data, int index) {
return UNSAFE.getByte(data, BYTE_ARRAY_BASE_OFFSET + index);
}
- 这里就是调用jdk底层的unsafe实例,根据基础偏移量+index算出总偏移量,从而拿到连续的内存。
之后再选择一个safe的_getByte实现:
io.netty.buffer.PooledHeapByteBuf#_getByte
@Override
protected byte _getByte(int index) {
return HeapByteBufUtil.getByte(memory, idx(index));
}
跟进这个getByte方法:
io.netty.buffer.HeapByteBufUtil#getByte
static byte getByte(byte[] memory, int index) {
return memory[index];
}
- 可见,底层就是通过java数组获取。
说白了,unsafe可以理解为通过native法操作内存,而非unsafe就是普通的java方法。
由什么决定ByteBuf类型
看到这个标题,有人可能就会觉得:当然都是由用户决定啊。
的确,无论是否Pooled,是head还是direct都是由用户选定的类、选定的方法决定的,但是是否是unsafe,这个就应该由Netty来控制了,就如jdk底层的Unsafe类一样。
下面就随便挑一个创建ByteBuf的方法看看。
我这里想创建一个Pooled、direct的ByteBuf,那么官方推荐使用PooledByteBufAllocator的接口,我这里就遵循官方找到如下方法:
io.netty.buffer.PooledByteBufAllocator#newDirectBuffer
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
if (PlatformDependent.hasUnsafe()) {
buf = UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
}
return toLeakAwareBuffer(buf);
}
- 可见,是否选用unsafe是由Netty判断能不能拿到底层的unsafe决定的。
- 当然这只是官方推荐的,要是水平够高不怕翻车,自己操作Netty的unsafe甚至是jdk底层的Unsafe也是没问题的~
如果你想创建Unpooled+direct类型,那么就调用io.netty.buffer.UnpooledByteBufAllocator#newDirectBuffer,创建head类型同理,客户都可以通过Netty提供的开箱即用的接口创建。unsafe是个例外,最好交给Netty控制。
小结
- ByteBuf类型主要分为:Pooled,Unpooled,Direct,Heap,unsafe,非unsafe。
- Netty提供给用户的接口中,是没有直接创建unsafe类型的接口的,因为unsafe是直接操作内存的,普通人使用unsafe可能会对开发环境造成直接伤害。
- unsafe和非unsafe类型的区别主要在于它们的读写等方法,如上面的_getByte方法。