文章目录
前言
本来在上一节写完UnPooledByteBufAllocator后,打算继续记录PooledByteBufAllocator创建ByteBuf的过程的。但是追PooledByteBufAllocator的原码需要非常多的前置知识,也就是本节要讲的。
本节主要讲PooledByteBufAllocator为ByteBuf分配内存时,预定义的内存规格、缓存&结构、chunk、arena、page、subpage等概念做一个介绍。
另外有一点非常重要的前提:PooledByteBufAllocator的内存分配是参考jemalloc实现的,所以建议看本文之前,先去看看jemalloc相关的博客。
以下是官方推荐的jemalloc参考资料:
- https://www.bsdcan.org/2006/papers/jemalloc.pdf
- https://www.facebook.com/notes/facebook-engineering/scalable-memory-allocation-using-jemalloc/480222803919
以下是我查到关于jemalloc描述的中文博客,同样非常建议花些时间去读:
如果上述资料都不看就直接学PooledByteBufAllocator,那简直是灾难~
Netty Version:4.1.6
内存规格介绍
这里先贴一下jemalloc的内存规格,方便对比:
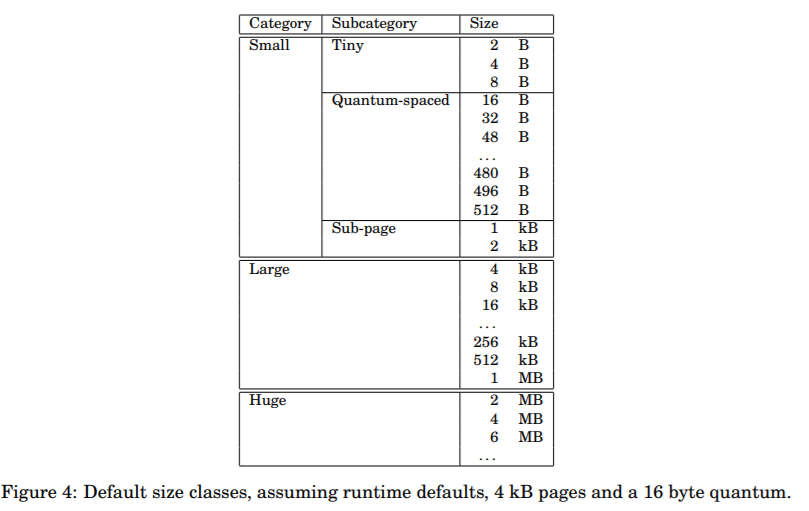
- 在jemalloc中一个page的大小为4kb,而在Netty中一个page的大小为8kb,下文会继续讲到。
而Netty做了一些改动,大概像下面这个样子:
| Category | Size |
|---|---|
| Tiny | size < 512B |
| Small | 512B <= size < 8kB |
| Normal | 8kB <= size <= 16mB |
| Huge | size > 16mB |
那以上规格在源码中是如何体现的呢?我们必须找出来,不然光说无凭啊。于是我找到如下一一对应的源码:
三种规格
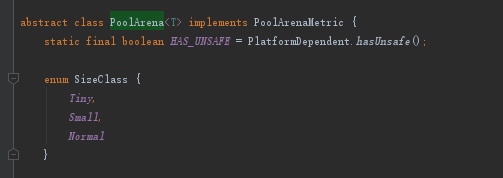
- 怎么没有Huge呢?这是因为它比较特殊,下面就会讲到。
Tiny规格TinySize < 512B
io.netty.buffer.PoolArena#isTiny
// normCapacity < 512
static boolean isTiny(int normCapacity) {
return (normCapacity & 0xFFFFFE00) == 0;
}
Small规格:512B <= SmallSize < 8kB
io.netty.buffer.PoolArena#isTinyOrSmall
// capacity < pageSize
boolean isTinyOrSmall(int normCapacity) {
return (normCapacity & subpageOverflowMask) == 0;
}
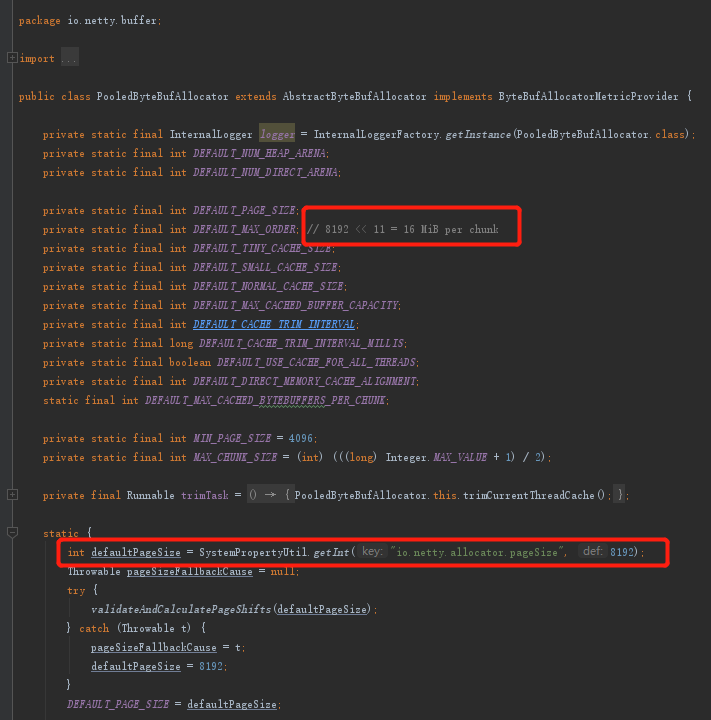
- subpageOverflowMask的值就是~(pageSize - 1),pageSize默认是8192B。
Huge、Normal规格:
io.netty.buffer.PoolArena#allocate(io.netty.buffer.PoolThreadCache, io.netty.buffer.PooledByteBuf
if (normCapacity <= chunkSize) {
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
allocateNormal(buf, reqCapacity, normCapacity);
} else {
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
- 可见,凡是大于chunkSize(16mB)的内存分配,都会被当做Huge,而8kB <= size <= 16mB就被当成Normal。
- 那为什么Huge不在SizeClass枚举中呢?其实前面的规格之所以在枚举中,主要是后边儿用于缓存时标记的。而Huge规格压根就不会缓存,所以不在SizeClass的枚举中。
好了,介绍完规格后,该介绍一下chunk、page等概念了。
Chunk、Page、SubPage介绍
如果你对MYSQL的页的数据结构、概念等比较熟悉,相信这三个东西理解起来是相当简单的。不过没有也没关系,这三玩意儿的概念还是很简单的。
其实这里分的概念和源码是有些出入的
下面先简单画个图,然后开始介绍:

Chunk
chunk是Netty向操作系统申请内存的最小调度单位,根据上图,chunk大小固定为16mB,也就是说,Netty每次向操作系统申请内存最小为16mB。
Page
上面说了一个chunk大小是16mb,如果Netty每次分配一个ByteBuf,都用掉一个chunk的大小,那显然太浪费了。
于是设计者们就决定将一个chunk划分为2048个Page,每个Page大小为8kb,Page是给ByteBuf分配内存的最小调度单位,尽管还有更小的subpage级别,但是分配subpage时,仍然需要先拿到一个page。
当ByteBuf需要申请的内存大小(必定是2的幂次方) >= 8kb时,会先取一个chunk,然后会以page级别分配内存,最后将当前chunk标记为“使用了一个部分”,然后放进对应占用率的chunkList。
源码体现(chunk和page)
chunk和page的大小:
SubPage
当ByteBuf需要申请的内存大小(必定是2的幂次方)< 8kb时,比如现在需要size=2kb,则会先取一个chunk,然后再取一个page,然后将page分成4份(pageSize/size),每一份为2kb,然后取其中一份给ByteBuf初始化。
之后就是一个自底向上标记的过程了,将当前使用的一份subpage标记为“已使用”,上一层page标记为“部分使用”,再上一级chunk标记为“部分使用”,最终也是将chunk放进对应占用率的chunkList。
最终,画个图整理一下就是下面这样:
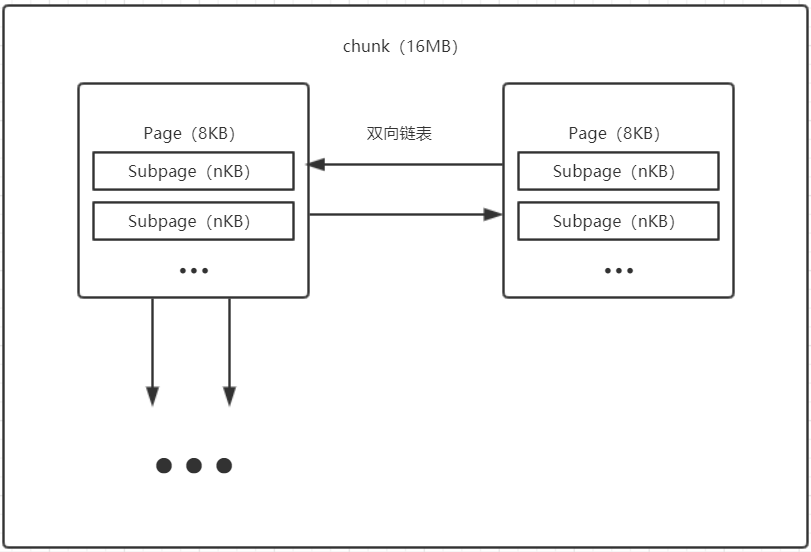
关于双向链表结构,可以去看看Netty中PoolSubpage这个类的源码属性。
Page和Subpage需要注意的点
需要注意的是,上文的page和subpage只是抽象分离出来的概念,在源码中只能找到PoolSubpage(就是对应page),倘若需要细分到抽象的subpage级别,PoolSubPage会被分成(pageSize/申请Size)份,并用bitmap记录每一份的偏移位置。
如果ByteBuf需求的内存 >= 8kb,那么甚至连PoolSubpage实例都用不上,完全就是根据chunk+偏移量取到连续内存,只是取的内存是以8kb为最小单位组合的,所以才会分出page的抽象概念。
Arena
Arena简介
在讲Arena是什么之前,先通过一张图直观感受下(jemalloc):
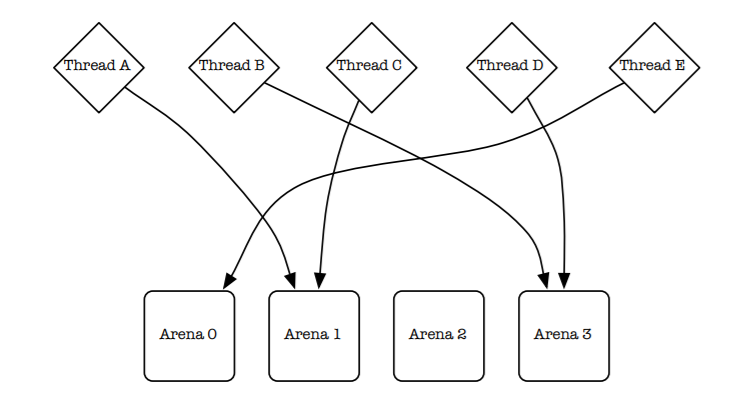
简单来说,Arena就是一个内存分配器,所有分配的内存都是由Arena维护的,并且一般会有多个,目的是减少锁竞争。
而netty则是对jemalloc的Arena进行能更加具体的实现,也就是netty中的PoolArena,我画了一张图,再来直观感受下:
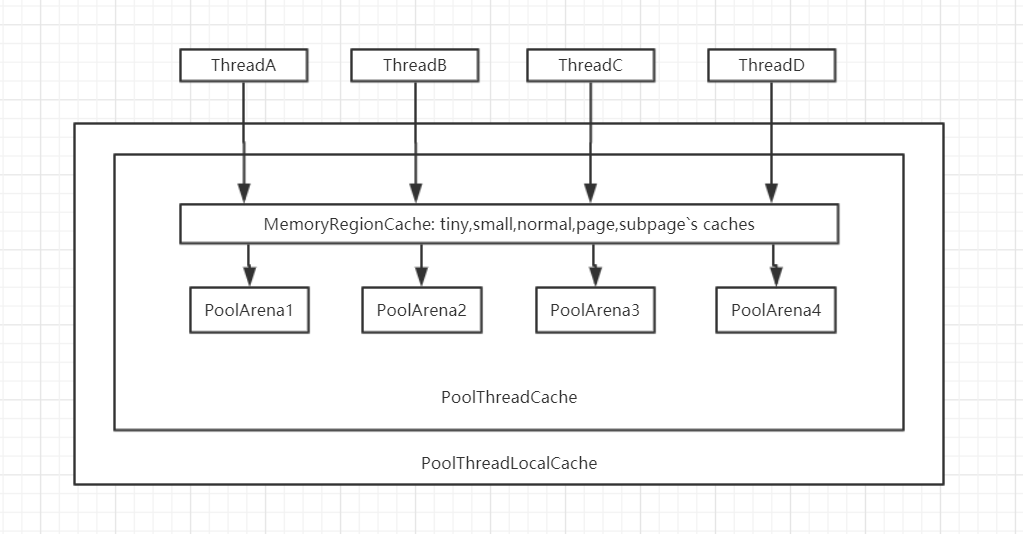
- 当请求分配内存时,会先尝试从缓存中取出相应内存,如果缓存没有,则穿透到Arena中分配内存。
- 在默认情况下,NioEventLoop的线程数 = 一种Arena的数量。
directArena分配direct内存简要流程(代码体现)
下面通过directArena分配direct内存简要流程来感受一下上一点图中的过程。
这里就以PooledByteBufAllocator创建direct类型的ByteBuf为例,也就是从以下代码开始看起(最好结合上面的图):
io.netty.buffer.PooledByteBufAllocator#newDirectBuffer
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
if (PlatformDependent.hasUnsafe()) {
buf = UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
}
return toLeakAwareBuffer(buf);
}
- 首先会从PoolThreadLocalCache中获得PoolThreadCache(可复用对象)。
- 然后从PoolThreadCache中获取到了directArena(分配heap类型内存就是获取heapArena)
由于heapArena和directArena都是初始化好的(下文会讲到),所以跟进directArena.allocate方法,最终见到类似以下代码:
io.netty.buffer.PoolArena#allocate(io.netty.buffer.PoolThreadCache, io.netty.buffer.PooledByteBuf
...(很长,略)
if (normCapacity <= chunkSize) {
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
allocateNormal(buf, reqCapacity, normCapacity);
} else {
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
- 如cache.allocateNormal就是尝试从Normal相关的缓存池中取对应大小的内存。
- 如果cache.allocateNormal返回false,则表示缓存中没有可用内存,然后调用allocateNormal方法才是真正从directArena中分配内存。
最后,除非宿主机内存不够或者OOM,不然都会分配到内存给ByteBuf并返回。
这里的流程现在看不懂也没什么关系,但最好对这流程留个印象,后面的博客会更加详细的跟进这个分配内存的过程。
Netty中Arena的初始化
这里还是拿PooledByteBufAllocator举栗子,见下图:
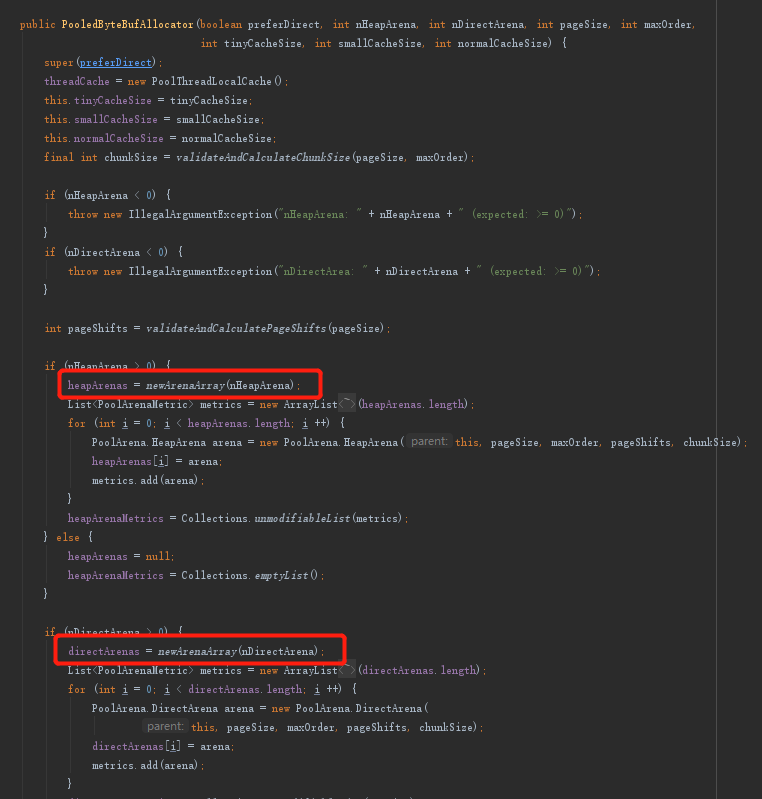
跟进newArenaArray方法看看:
io.netty.buffer.PooledByteBufAllocator#newArenaArray
@SuppressWarnings("unchecked")
private static <T> PoolArena<T>[] newArenaArray(int size) {
return new PoolArena[size];
}
- 其实就是构建PoolArena数组对象,返回后再由PooledByteBufAllocator构造方法继续填充元素。
再试着追一下PoolArena的size,就能明白size的含义了:  - 也就是默认情况下,和[NioEventLoop的线程数量](https://wenjie.store/archives/netty-nioeventloop-build-1)是一样的,**这样能最大限度的减少不同线程之间的竞争**。
那么PoolThread又是怎么获取到PoolArena对象的呢?看看PoolThreadLocalCache初始化PoolThreadCache的方法就知道了:

PoolArena的数据结构
在了解完chunk内部结构以及什么是Arena后,现在不妨来看看PoolArena的数据结构,我借用了网友的一张图:
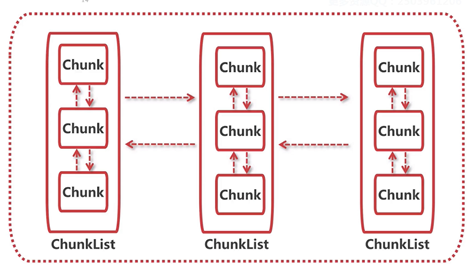
- 可见就是chunk、chunklist的双向链表。
需要注意的是这里每个ChunkList都存储着不同占用率的Chunk,这点其实也是参考jemalloc的思想,见下图:
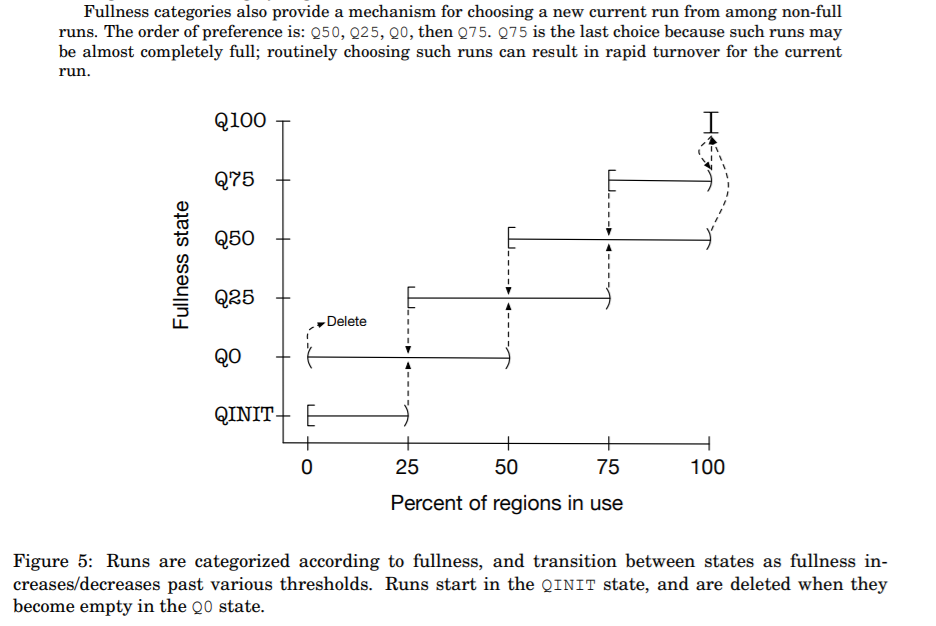
下面看看源码的体现相信就能豁然开朗了。
源码体现(PoolArena)
看看PoolArean的属性:
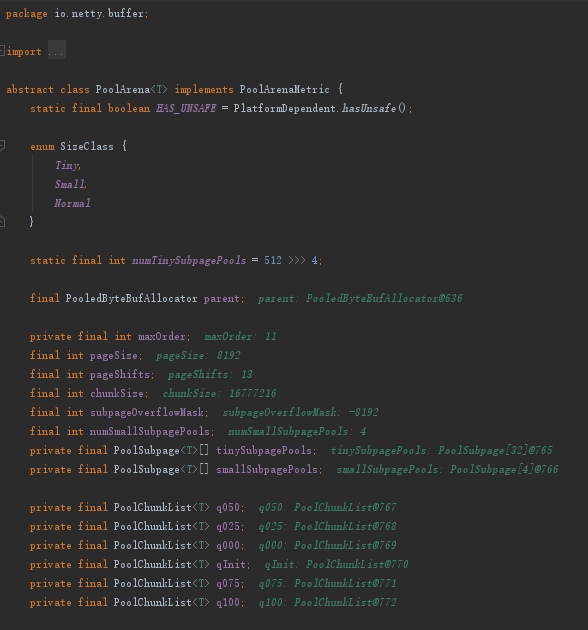
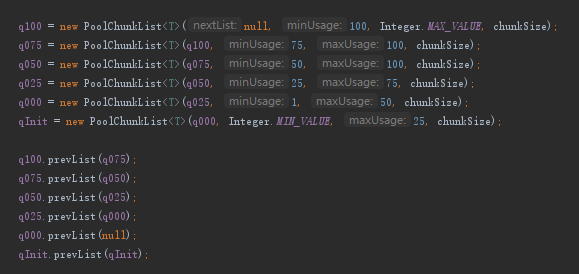
- q025就表示这个ChunkList都存储着占用率25%~75%的chunk,其它类型如代码所示。
继续看看ChunkList的属性:
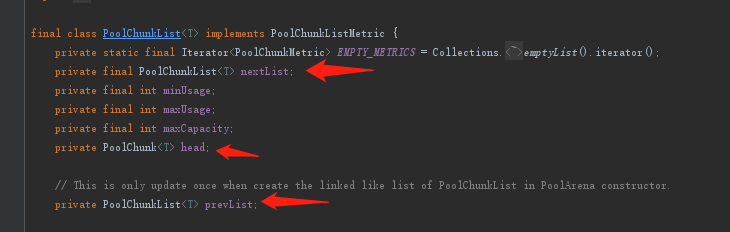
- 明显是双向链表结构,并且存储了PoolChunk的头结点。
再看看Chunk的属性:
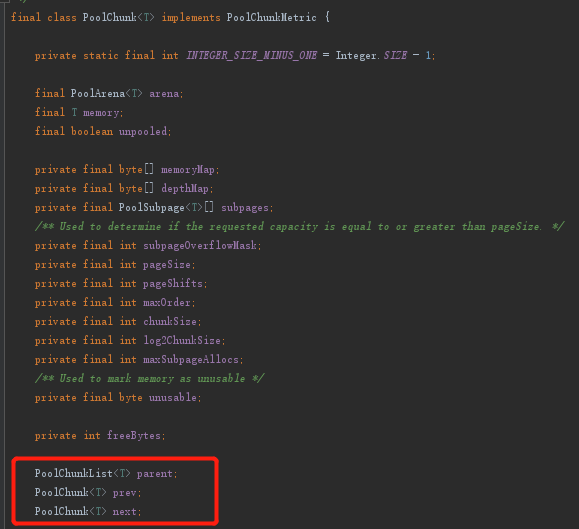
- 同样明显有双向链表结构,并记录了所属的ChunkList。
- 这里的memory在ByteBuf简介这篇提到过,其它参数大部分都是为了memory而服务的。
缓存&结构
简介(含结构图)
其实Netty的内存缓存依然是参考jemalloc的。
下面借用一下网友描述内存缓存的图:

- 缓存最大只支持到32kB,大于32kB的都不会缓存。
- 数组的每一个元素都是一个MemoryRegionCache,并且三种规格的内存都缓存在不同MemoryRegionCache中。
- 这里的“红心节点”都表示head节点,是无效的,只有当ByteBuf使用完内存,才会将用完的内存缓存到MemoryRegionCache的queue。
回收ByteBuf的源码追踪记录之后会写在另一篇博客,这里留个印象或者复习。
MemoryRegionCache:

- 作者可能拼写错误了,handler应该改为handle,这个handle属性是在
io.netty.buffer.PoolThreadCache.MemoryRegionCache.Entry,只是MemoryRegionCache在被回收时,可能被封装到Entry中。 - 关于handle,以后遇到就能明白什么意思了,这里只能简单介绍下:handle通过一定位运算存储了bitmapIdx和memoryMapIdx,可以理解为存储了内存的偏移量,chunk结合这个偏移量就能拿到唯一一段连续内存。
源码体现
下图中的属性就是不同内存规格的缓存,算上subpage一共6种:
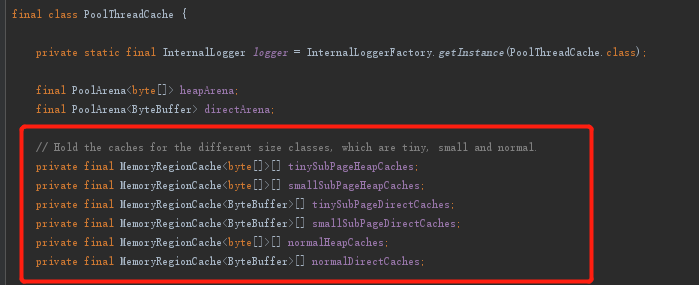
挑tinySubPageHeapCaches的初始化来看看:
tinySubPageHeapCaches = createSubPageCaches(
tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny);
tinyCacheSize就是queue的长度,三种规格队列长度默认值如下:
// cache sizes
DEFAULT_TINY_CACHE_SIZE = SystemPropertyUtil.getInt("io.netty.allocator.tinyCacheSize", 512);
DEFAULT_SMALL_CACHE_SIZE = SystemPropertyUtil.getInt("io.netty.allocator.smallCacheSize", 256);
DEFAULT_NORMAL_CACHE_SIZE = SystemPropertyUtil.getInt("io.netty.allocator.normalCacheSize", 64);
numTinySubpagePools默认为32,即上面结构图中tiny缓存数组的长度,三种不同规格默认值如下:
// tiny:32
static final int numTinySubpagePools = 512 >>> 4;
// small:4,pageShifts默认是13
numSmallSubpagePools = pageShifts - 9;
// Normal:3,max默认为32kb,即32678,pageSize默认是8kb,即8192
int arraySize = Math.max(1, log2(max / area.pageSize) + 1);
跟进createSubPageCaches方法:
io.netty.buffer.PoolThreadCache#createSubPageCaches
private static <T> MemoryRegionCache<T>[] createSubPageCaches(
int cacheSize, int numCaches, SizeClass sizeClass) {
if (cacheSize > 0) {
@SuppressWarnings("unchecked")
MemoryRegionCache<T>[] cache = new MemoryRegionCache[numCaches];
for (int i = 0; i < cache.length; i++) {
// TODO: maybe use cacheSize / cache.length
cache[i] = new SubPageMemoryRegionCache<T>(cacheSize, sizeClass);
}
return cache;
} else {
return null;
}
}
这里就创建了MemoryRegionCache数组,数组中的每个MemoryRegionCache都负责缓存不同大小的内存块。
- 还有个长得不一样的createNormalCaches方法,这个有兴趣就自己补充下吧,核心逻辑都一样的。
试着看看MemoryRegionCache的属性:
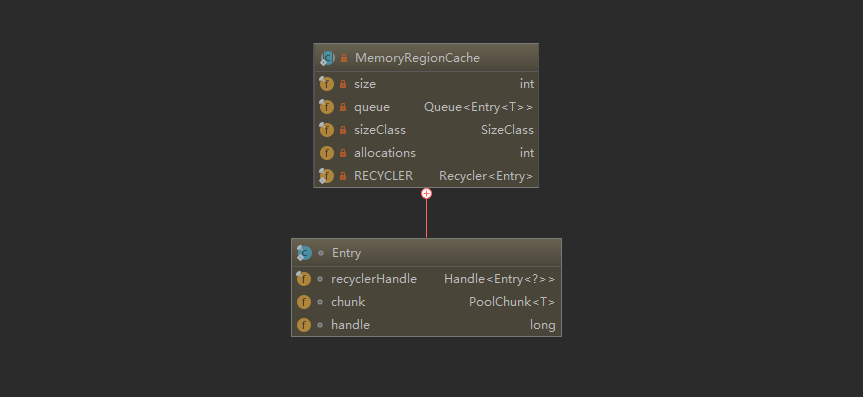
- 与上面结构图出现的queue、handle、chunk一致。
完