前言
最近公司方面还在不停熟悉业务,Unreal方面暂时蓝图战士不太好以博客方式记录
于是就先水一篇内存泄露OOM(比较简单) & Full GC(比较意外)的排查
OOM问题
这个问题虽然最后定位的时候很简单,但是过程比较坎坷🤣
问题现象
在3月中旬的某个早上,出现了一次预发请求不通的问题,起初以为只是个例,就不太重视

但自从这一天起,预发就天天隔一段时间就接口不通,偏偏线上又很稳定,非常诡异
后来发现是hsf(内部RPC)自动下线了
再后来,这个问题还一直存在,由于我所处的业务是C端入口,挂掉很影响其它域的开发、测试、验收,于是我也被派来查问题了
趁着一次hsf服务下线的时候,经过多种尝试,最终进docker容器看进程的时候发现异常,应用进程其实已经挂掉了(所以才导致hsf服务下线了):

之后再查看这机器的监控,发现内存一直在缓缓增长,到85%(JVM 12G 物理内存16G)左右的时间刚好跟hsf服务下线的时间差不多,此时基本可以断定为:发生了内存泄露,顶满JVM导致被系统杀死
什么东西泄露了
上面虽然基本确认是内存泄露,但到底是什么东西泄露还是很迷惑,因为表象是这样的:预发直接部署master分支的代码,但依旧会出现内存升高最终OOM
如果拿预发的配置再跟线上一一比对排查,效率就太低了,所以决定抓取内存快照(
hprof)来看问题由于docker环境下没有
jmap这种工具,也无法上传,所以我使用了如下两种方式抓取快照:后来应用再崩溃,成功抓到的快照文件,就直接丢进
mat解析了,一眼就看到了问题所在:

最终根因:是N早之前内部接入的doom(类似jvmsandbox)录制导致内存泄露了,最终OOM Crash了(这东西只在预发接了)
解决方式:doom这东西是淘天接过来的,把证据怼他们脸上提工单🤣
至此,持续一个多月的“预发离奇下线案”,总算结束了

Full GC问题
背景
发生Full GC的应用是一个ToB工具,我最近也要在里面增加一些代码逻辑
刚接手的时候,没有留意现有的监控,应用的管理员也掉线了,监控的有效期只有一个月
而恰好是我改动后的一个多月,该应用的管理员突然上线了,然后一查监控发现了一堆Full GC
管理员翻了翻最近的发布记录看到都是我,于是就让我接锅了
问题现象
说实话,一开始我也以为是我搞出来的Full GC,因为我加了一条很长的数据处理链路,持有对象的生命周期是有点长
但是,经过如下验证后很快就否掉了是我问题的可能性:
我的任务有配置开关,关掉以后应用也一直在Full GC
这个应用一天能Full GC 20W次,这个数据太不正常了
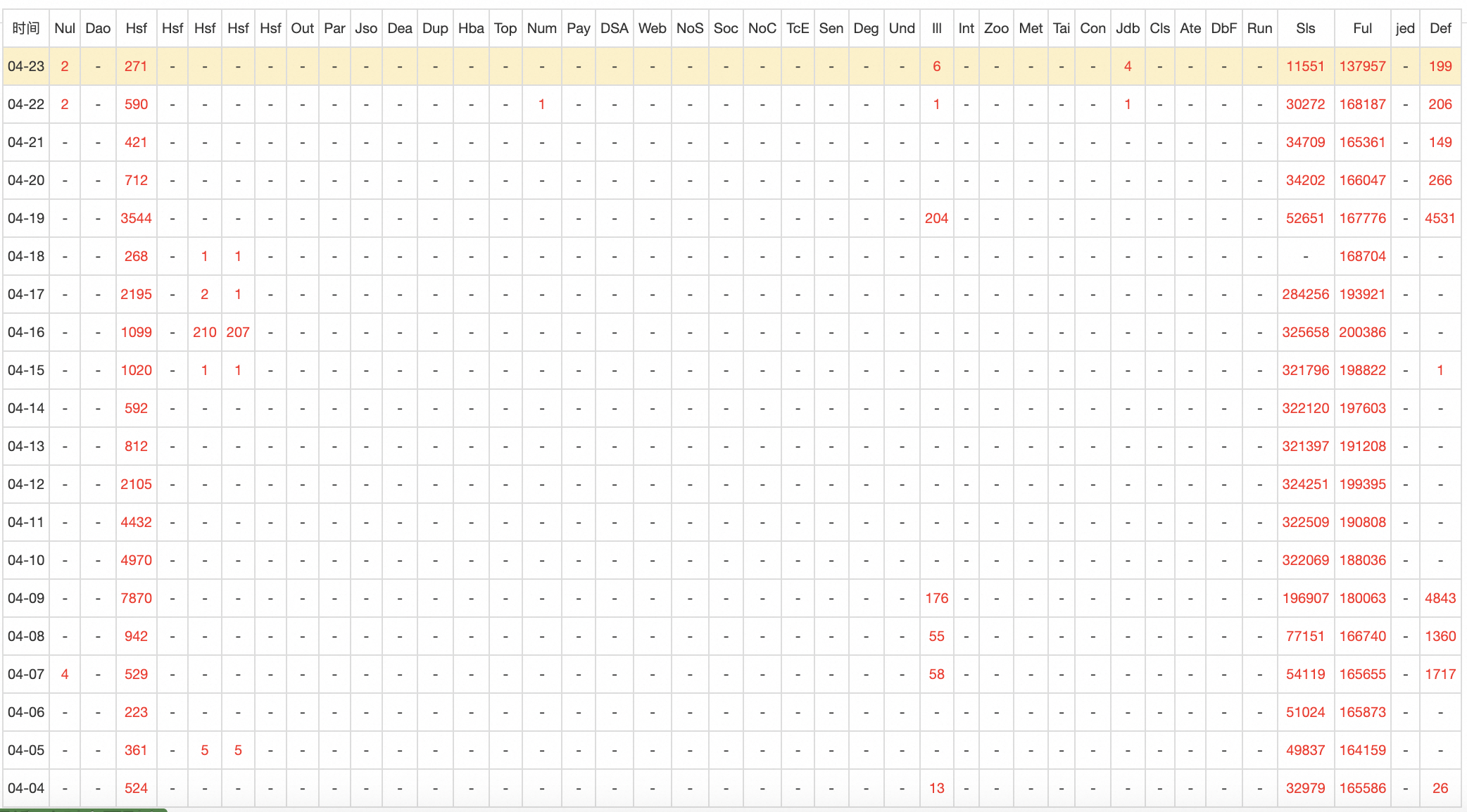
虽然我自己能排除自己的嫌疑,但奈何不住历史监控缺失 + 最近发布的人只有我,锅还是甩不掉哇🐸,所以我只能把根因也揪出来
开始排查前,先回归了下造成Full GC的主要原因:
老年代空间不足:通常是内存泄漏、大集合等,概率高
永久代或元空间满:可能是某些static元素太大,概率中
调用
System.gc():一般没人主动调这东西,概率很低
问题排查
首先是确认概率最高的内存泄漏、大集合,结果竹篮打水一场空,内存快照全都是正常的框架引用,甚至都找不到几个业务对象的引用(com.taobao开头的都是内部框架、sdk):
到这一步可以对现有的可能性进行梳理:
框架的BUG,持有太多大对象了(排除,毕竟是上过生产的东西,占用内存还算合理范围内)
内存泄漏(排除,内存没有不断上涨,diff了前后2份快照,大对象数量并没有膨胀)
JVM配置出错(概率很小,发布平台默认配置好好的,真有人去动?)
到这里我还是比较诧异的,因为按照我以前写过 & 修复过的内存问题来看,出问题90%+都是因为内存泄漏,而这次内存快照看起来却十分的“健康”。这让我短时间内陷入混乱,开始想方向是不是错了


然,终究是皇天不负有心人,内存快照失利后,经过了短暂的“玄学”操作,想起以前查问题的时候JVM的内存分布好像没考虑过,于是就看了下应用的内存分布
结果不看不知道,一看就找到了显眼包:

64KB的老年代,这不对吧,于是立马也查下其它应用的老年代,发现都是跟年轻代55开的:

此时问题基本确认了,应用JVM的老年代太小了,导致一天有20W的Full GC
问题修复
查看应用的启动命令,可以看到:

如上图所示heap size=2GB,年轻代 size=2GB,老年代size=heap-年轻代=0,于是就变成64KB
为什么=64KB查了下没查到,估计跟老年代最小内存分配单位有关,掏底层源码估计很费劲,咕咕咕了🐦
非常Easy,就是把年轻代改成1GB,这样2GB(heap) - 1GB(年轻代) = 1GB(老年代):
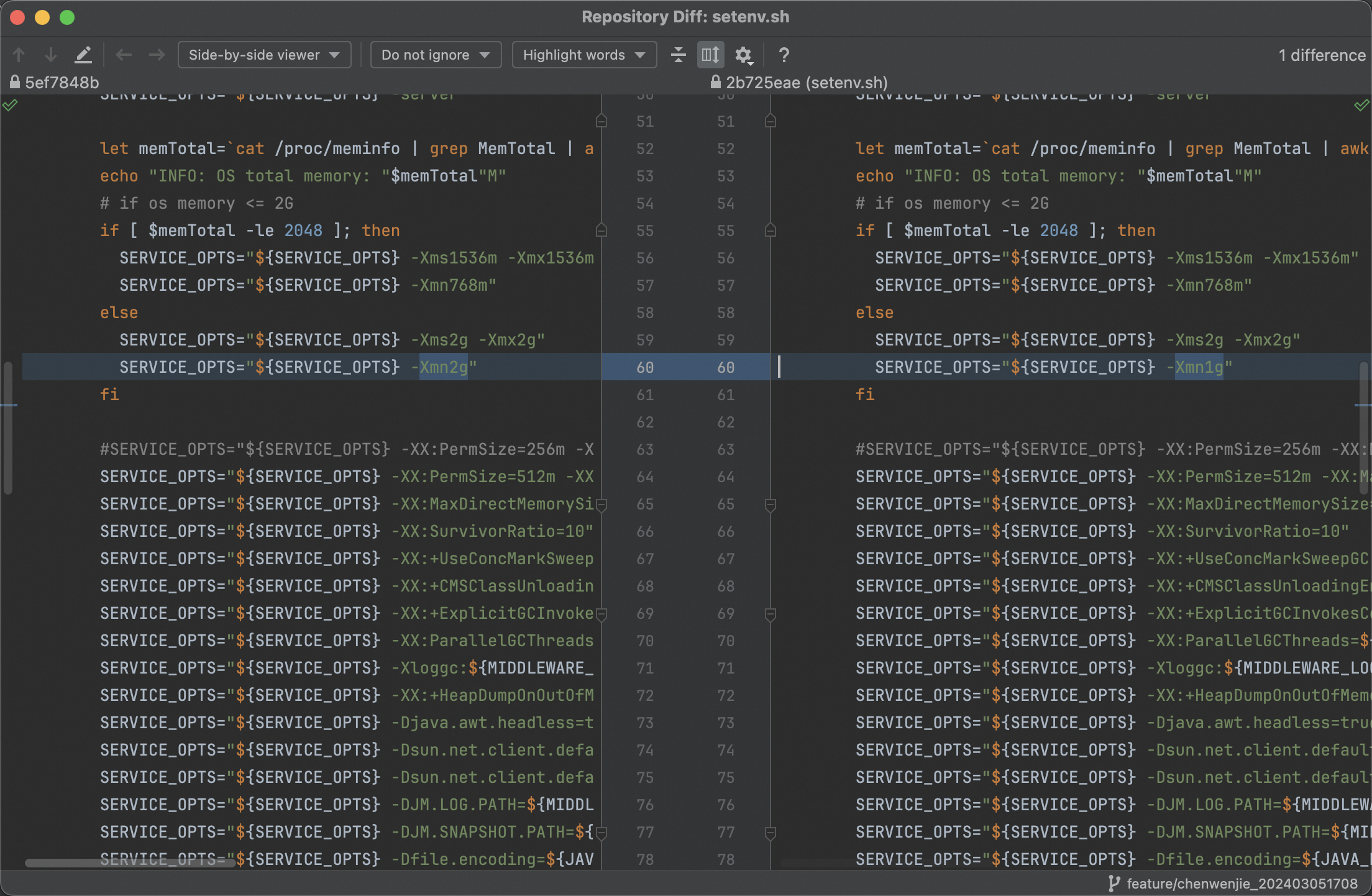
之后重新检查启动命令确保是生效的:

观察监控,Full GC清零:
到此为止,诡异的Full GC已然修复
问题是怎么发生的
修复这个问题很简单,无非是修改一下JVM参数重启
但,找到原因后,我更好奇这个问题是怎么发生的,于是我开始追溯这个问题是什么时候、以何种方式引入的
我先是工程里面看找配置了这个JVM参数的地点,这个就是最原始的灾难现场:
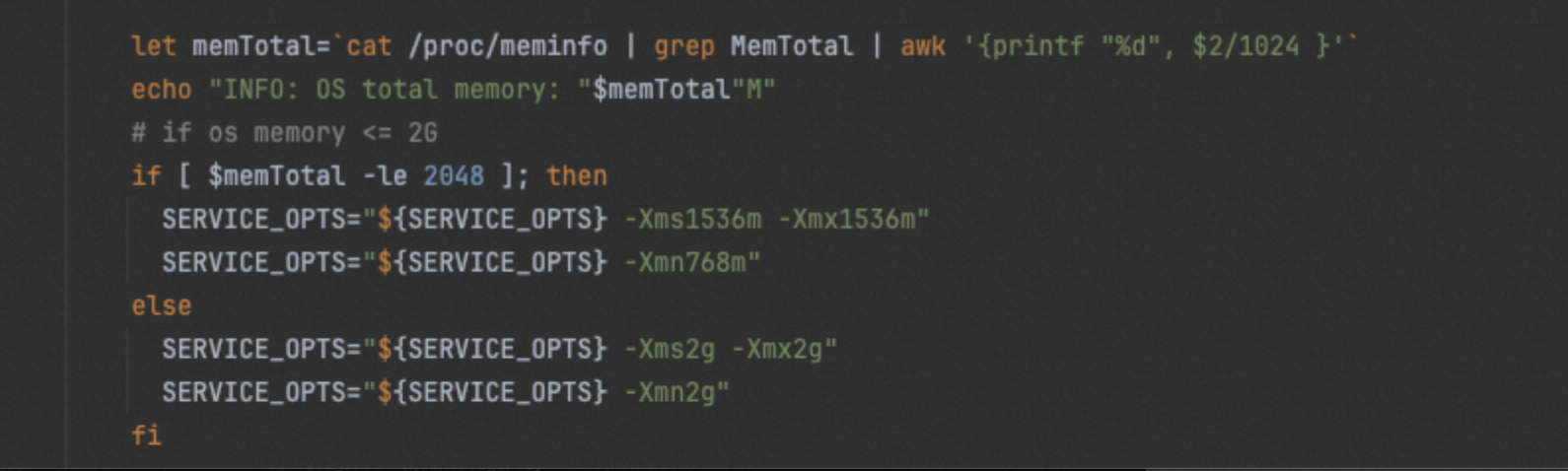
最后我们可以看看这次commit id对应的更改:
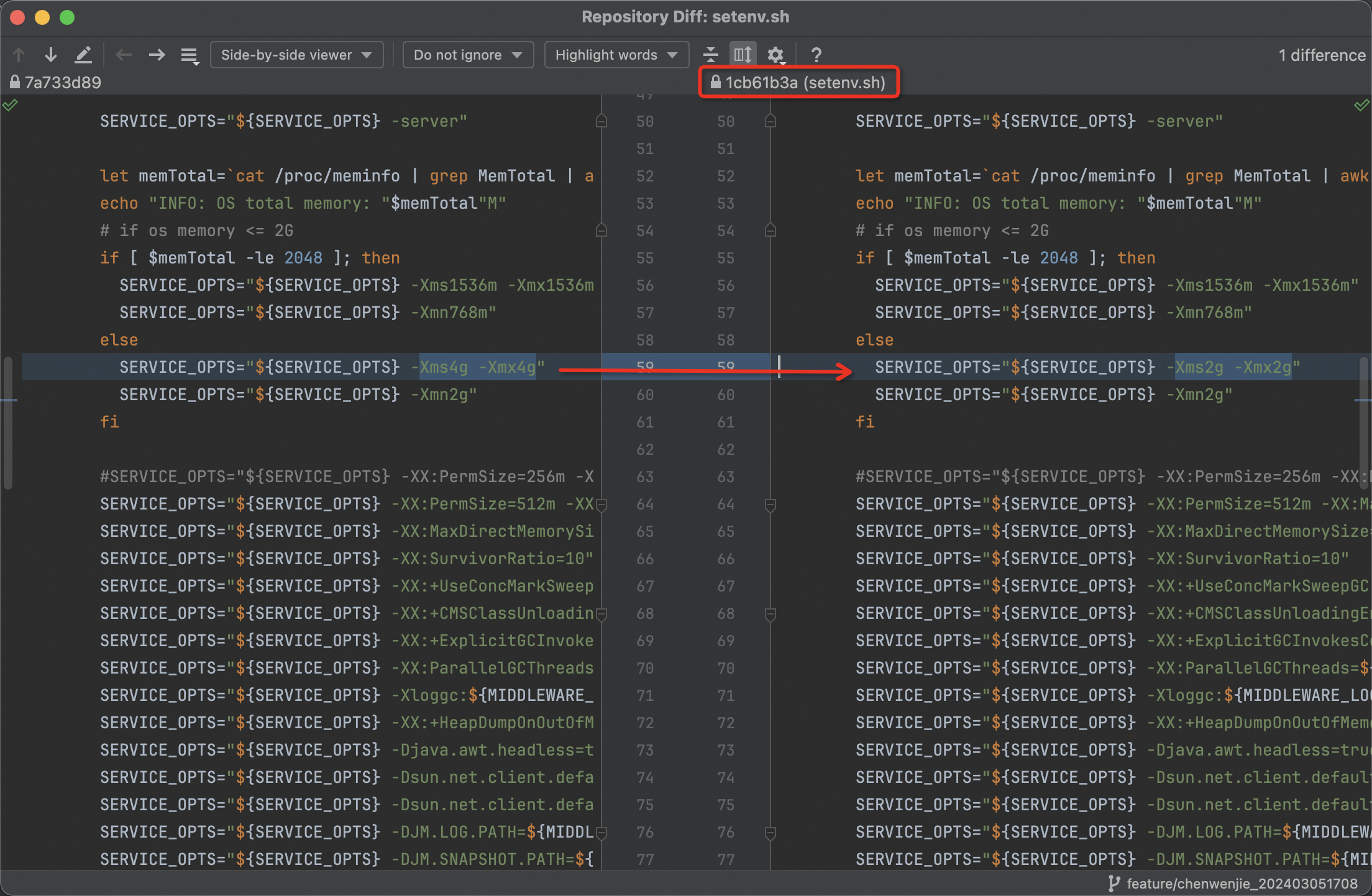
可以看到,之前是一个叫Xxx的用户,可能是因为之前机器缩容而修改JVM heap的min、max值;但他忘记修改年轻代的值,导致heap缩减到2GB后,年轻代也依旧是2GB,最终老年代哭诉无门,只能Full GC了