前言
最近在看一些书补下C的基础(大学第一门是C++,跟C还是有一点差异的),虽说大部分语法层面的内容都上手很快+容易记住,但涉及一些指针层面的东西,经常看完就忘了,所以还是决定以博客的方式记录下,方便后续自己 or 他人查阅。
mac无法更改指针来修改常量
我们先试着在win上用指针修改常量,发现是可以成功的👇🏻:
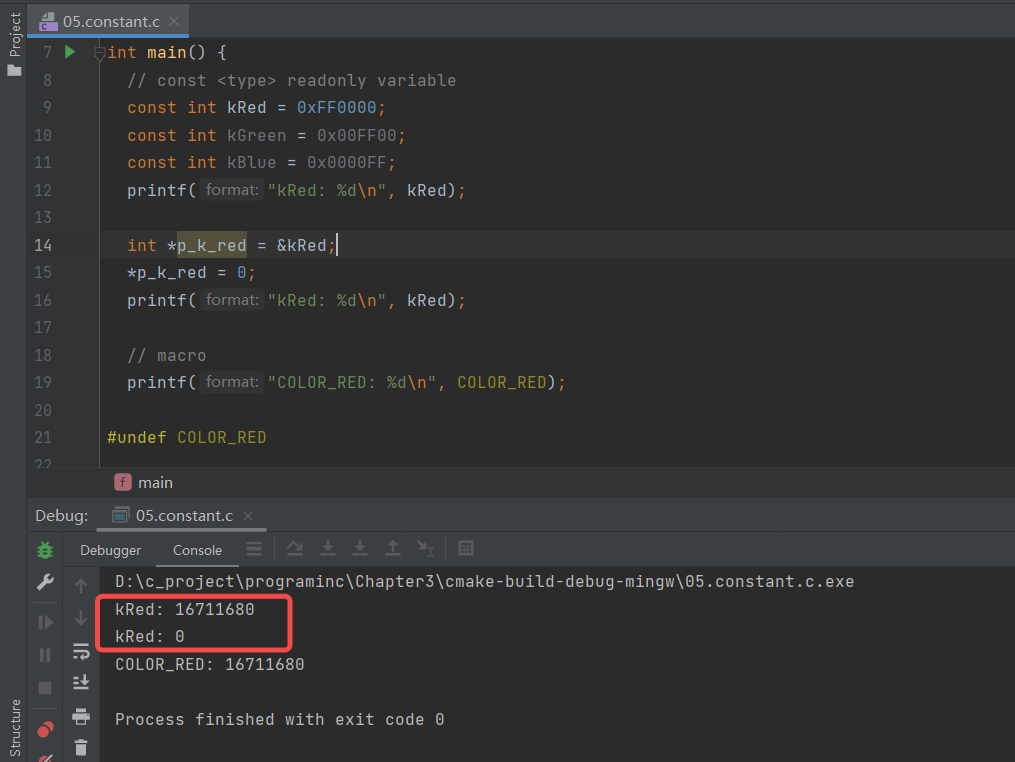
但是在mac上却失败了👇🏻:
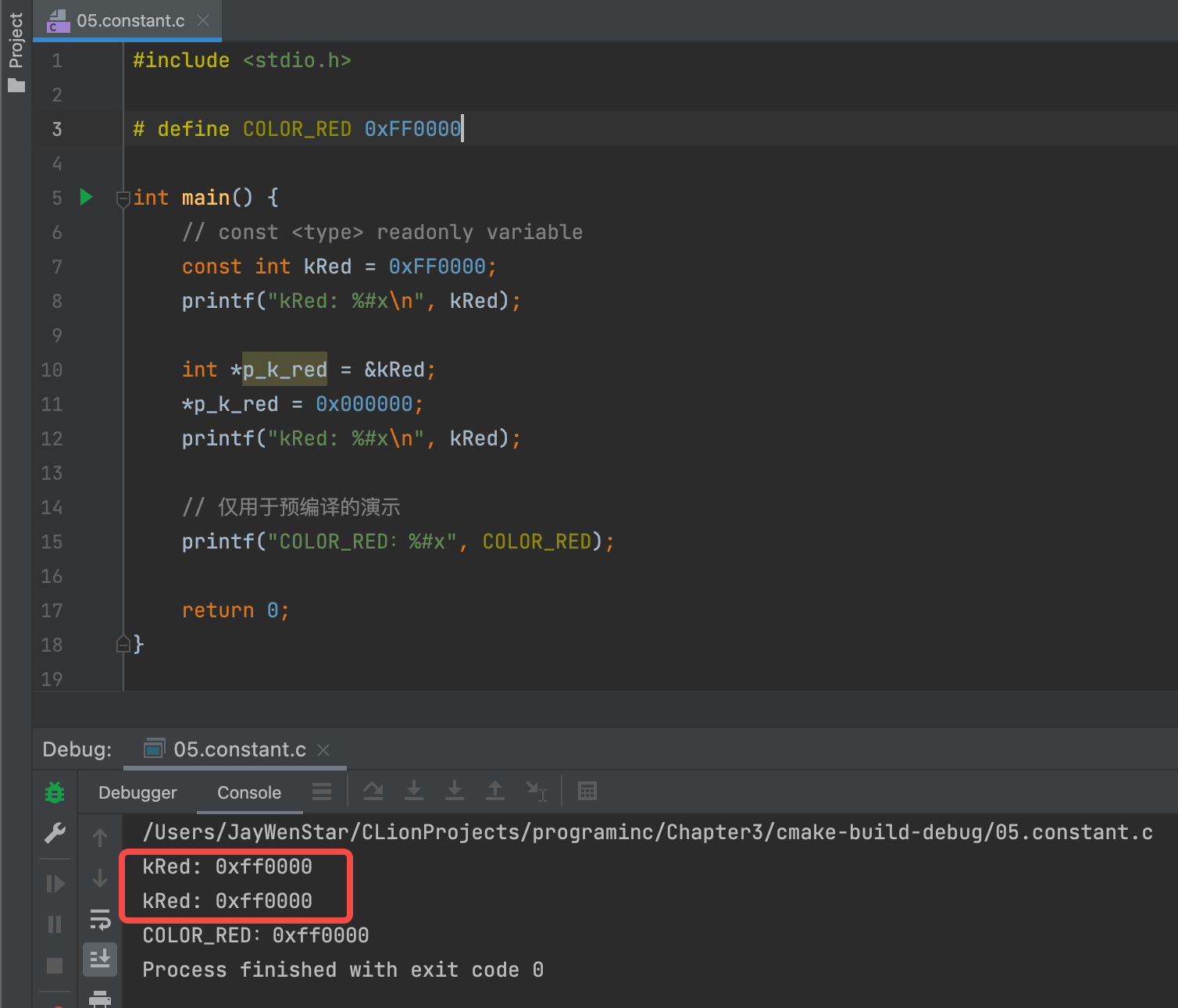
我一开始尝试debug引用查看内存是否发生变化,结果是变了的,如下图所示👇🏻:
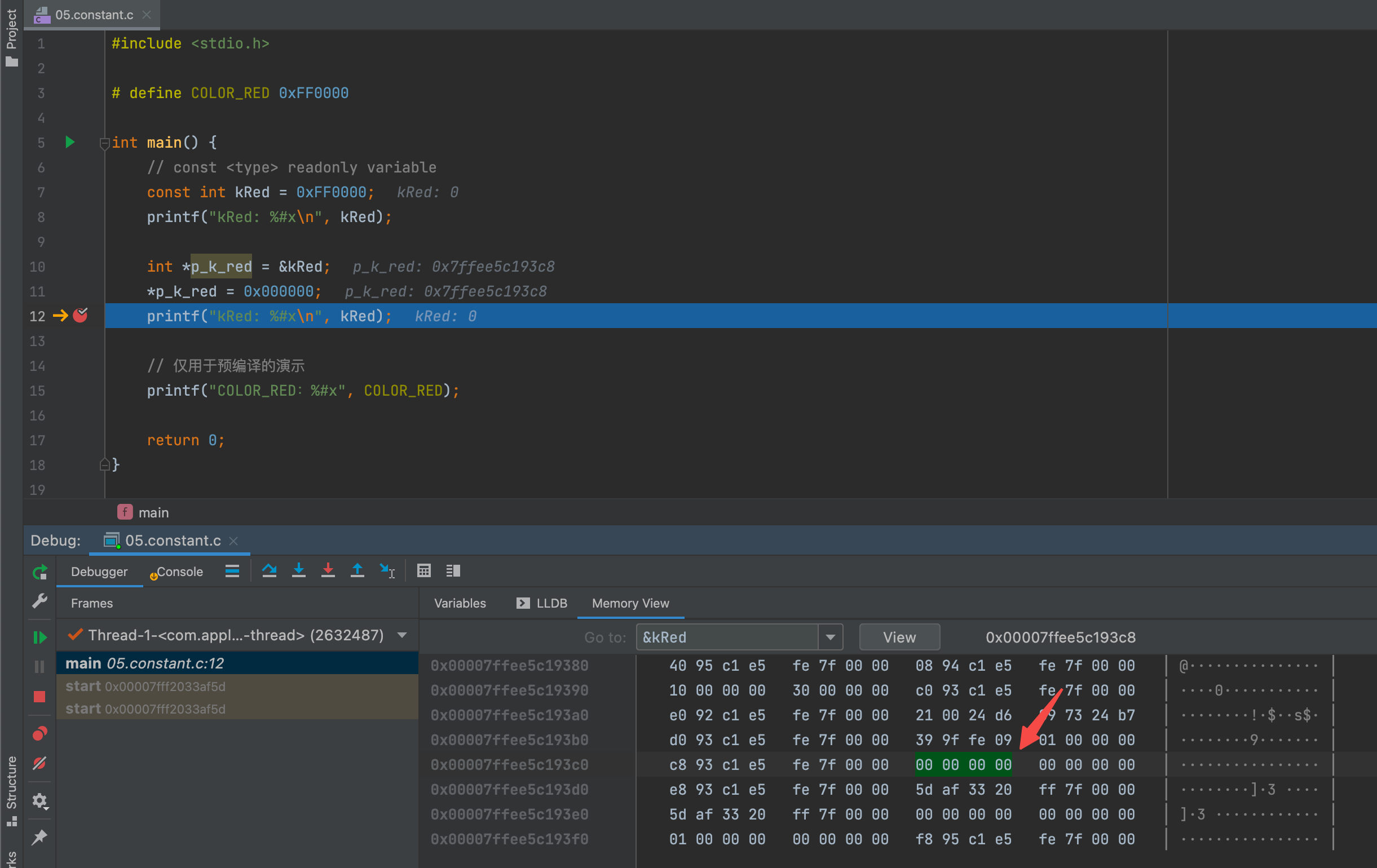
之后想了想会不会是预编译的时候做了跟宏一样的优化方式,也是预编译了一下,发现并不是,预编译后内容如下(可以看见宏已经被替换了)👇🏻:
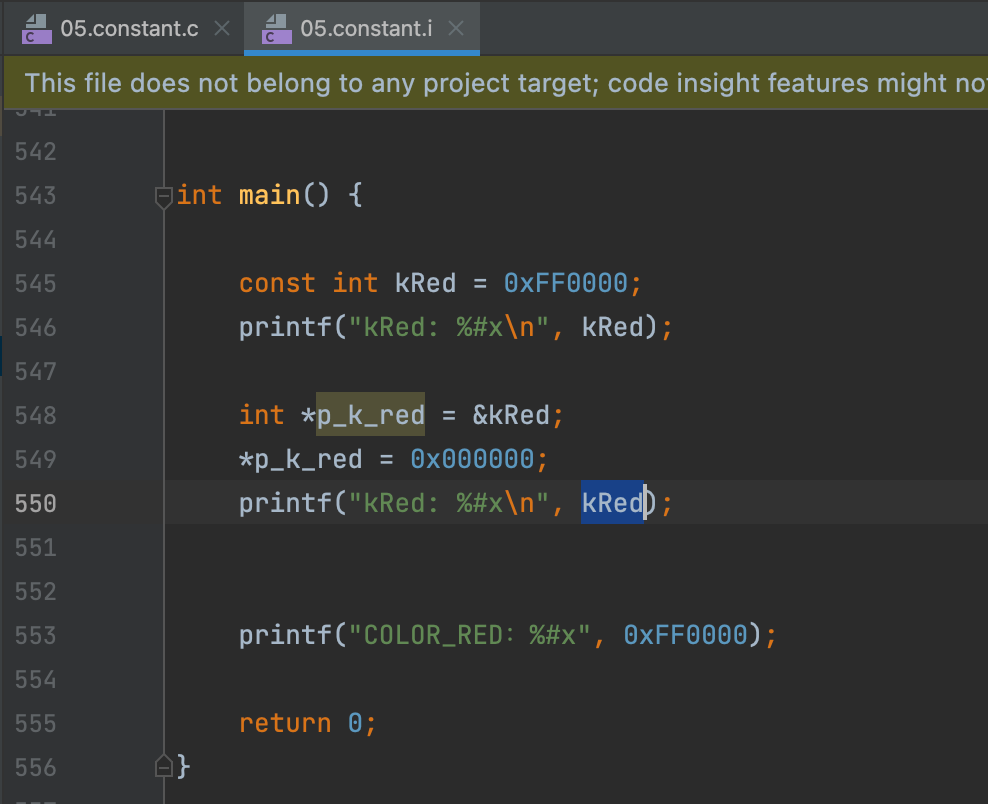
剩下的猜测只能是mac做了编译层的优化了,应该类似于Java的标量替换,意思是最终的代码做了跟宏差不多的事情👇🏻:
// 最终代码反编译可能就是这样的,至于是在哪层被优化了,之后可能要查看汇编指令等排查。
#include <stdio.h>
# define COLOR_RED 0xFF0000
int main() {
// const <type> readonly variable
const int kRed = 0xFF0000;
printf("kRed: %#x\n", kRed);
int *p_k_red = &kRed;
*p_k_red = 0x000000;
printf("kRed: %#x\n", 0xFF0000);
// 仅用于预编译的演示
printf("COLOR_RED:%#x", 0xFF0000);
return 0;
}
指针问题
以下内容绝大部分参考《C与指针》
基础概念
一条指针等式
先来看看,有下面这一段代码,*&x = 17;是什么意思?
# include "stdio.h"
int main() {
int x = 1;
printf("%#x\n", x);
*&x = 17;
printf("%#x\n", x);
return 0;
}
其实*&x = 17;等价于x=17,输出结果如下:
0x1
0x11
我们可以通过debug查看内存,*&x = 17;之前👇🏻:
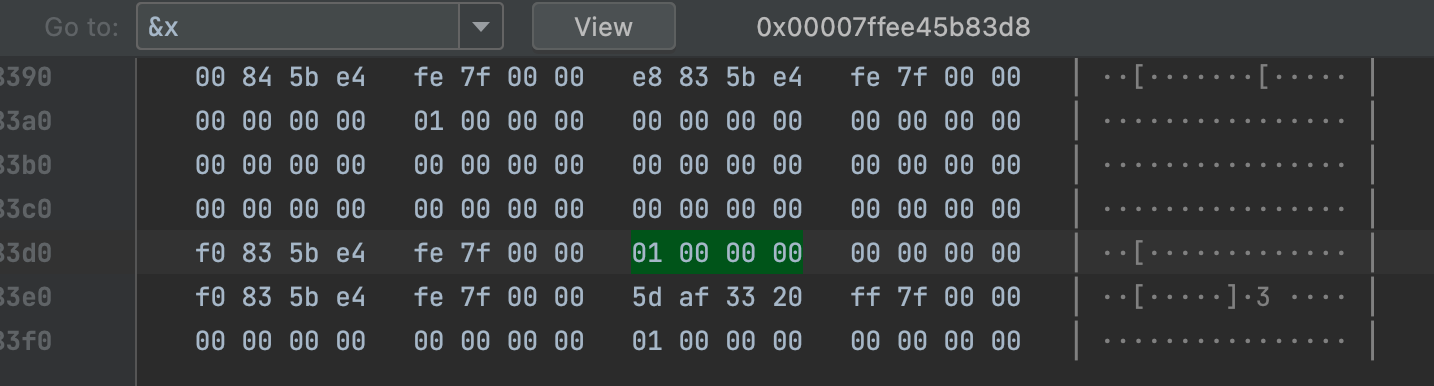
字节序倒过来是大小端的问题,这里不在展开。
*&x = 17;之后👇🏻:
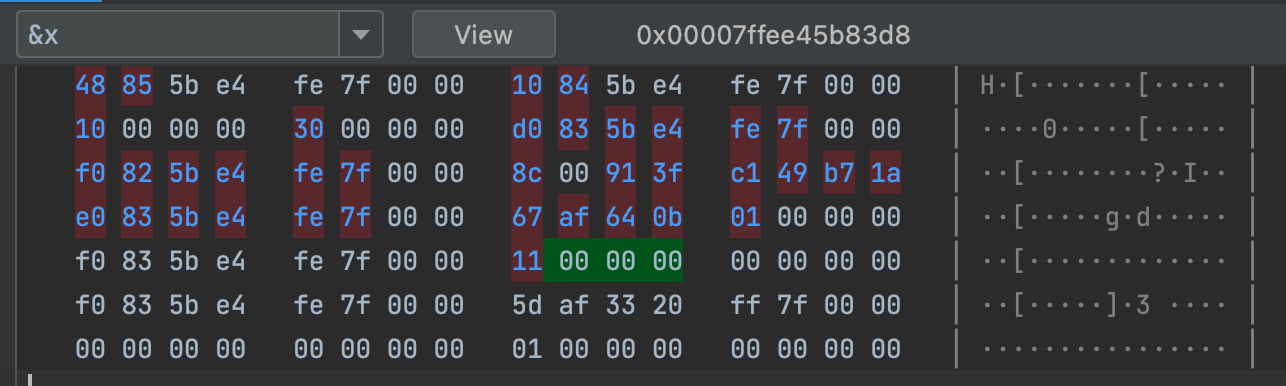
对于上述步骤,你可以把*&x = 17换成x=17,得到的结果是一样的,在这里只需要记住作为左值*&x = x就行了。
左值和右值下面就会介绍。
左值和右值
首先介绍下我理解的概念:
- 左值:表达式可以容纳右值,它必须指向一个明确的地址来存储。
- 右值:表达式的结果可以被赋予到左值,右值只能被存储 or 被指针用于间接访问。
这个概念第一次看的时候会比较懵逼,但多看几次后其实就没啥大问题了。
假设有如下代码:
int a = 1;
int *b = &a;
*b在这里就是左值&a在这里就是右值
那可不可以写这样一行代码呢?👇🏻:
&a = 2;
答案是不可以,因为&a的结果是16进制的地址,你可以理解为写下面这样的代码是非法的:
1 = 2;
如果这里看不懂那还没关系,后面说到指针表达式的时候,还会有很多例子。
指针的指针
我们来看下面一个代码例子:
# include "stdio.h"
int main() {
int a = 12;
int *b = &a;
int **c = &b;
printf("%d", **c);
return 0;
}
// 删除结果就是12
对于上面的例子,我们需要想起前面的一条等式,即*&x = x,我们可以通过约简来得到结果:
// 以下是已知条件
a = 12;
*b = &a; // 可以看做b = &a,*b = *&a = a = 12
// 开始约简
**c = &b也可以像上面那样先看做c = &b,然后👇🏻
**c = **&b = *b = *(&a) = a = 12
至少我通过这种方式记忆其实会好很多。
指针表达式
如果只是单个指针变量,通常看起来没什么难度,但如果是指针配合表达式,那么它的意思往往会跟我们想象的有些许偏差,下面就举一些例子,来说说一些表达式左右值的合法性和含义。
《C与指针》中会把右值放在表格左边,左值放在右边,看的时候带上自己的方向感会很容易混乱。。
前置代码如下:
int main() {
char ch = 'a';
char *cp = &ch;
}
- 我之所以用char,只是因为它刚好一个字节,便于到内存中根据偏移debug查看
先来看简单的,这部分就展开含义了,毕竟都是基础语法:
-
表达式
ch- 左值 ✅,
ch = 'b';成立 - 右值 ✅,
char cx = ch;成立
- 左值 ✅,
-
表达式
&ch- 左值 ❌,
&ch = 任何常量/变量/引用;不成立 - 右值 ✅,
char *cp = &ch;成立
- 左值 ❌,
-
表达式
*cp- 左值 ✅,
char *cp = &ch;成立 - 右值 ✅,
char cx = *cp;成立
- 左值 ✅,
接下来看一些比较复杂的:
-
表达式
*cp + 1- 左值 ❌:
*cp + 1 = 任何不成立 - 右值 ✅:
ch = *cp + 1;成立 - 含义看例子就懂了👇🏻:
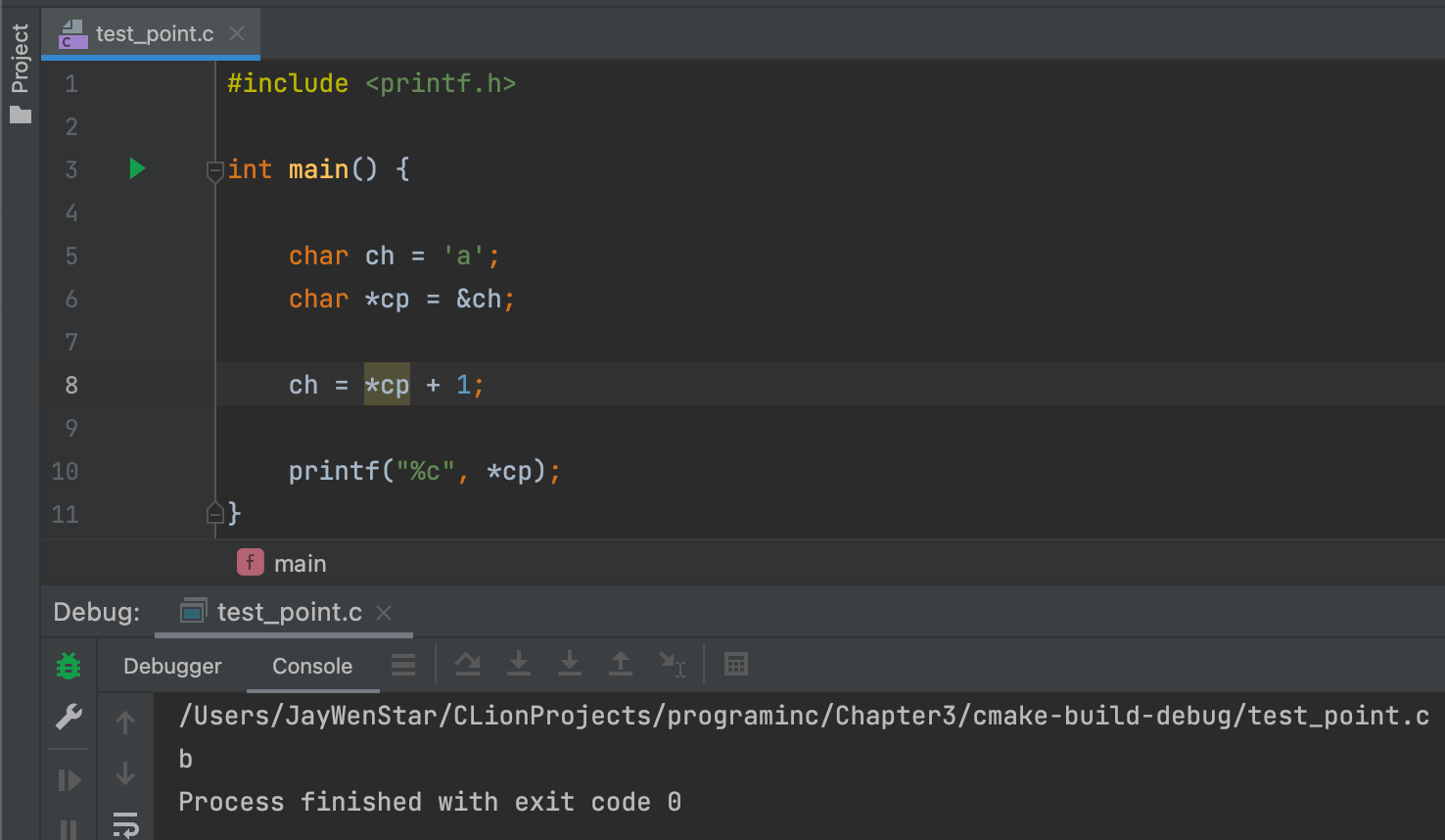
*cp + 1就是*cp就是取出a的ASCII码+1,结果就是b。
- 左值 ❌:
-
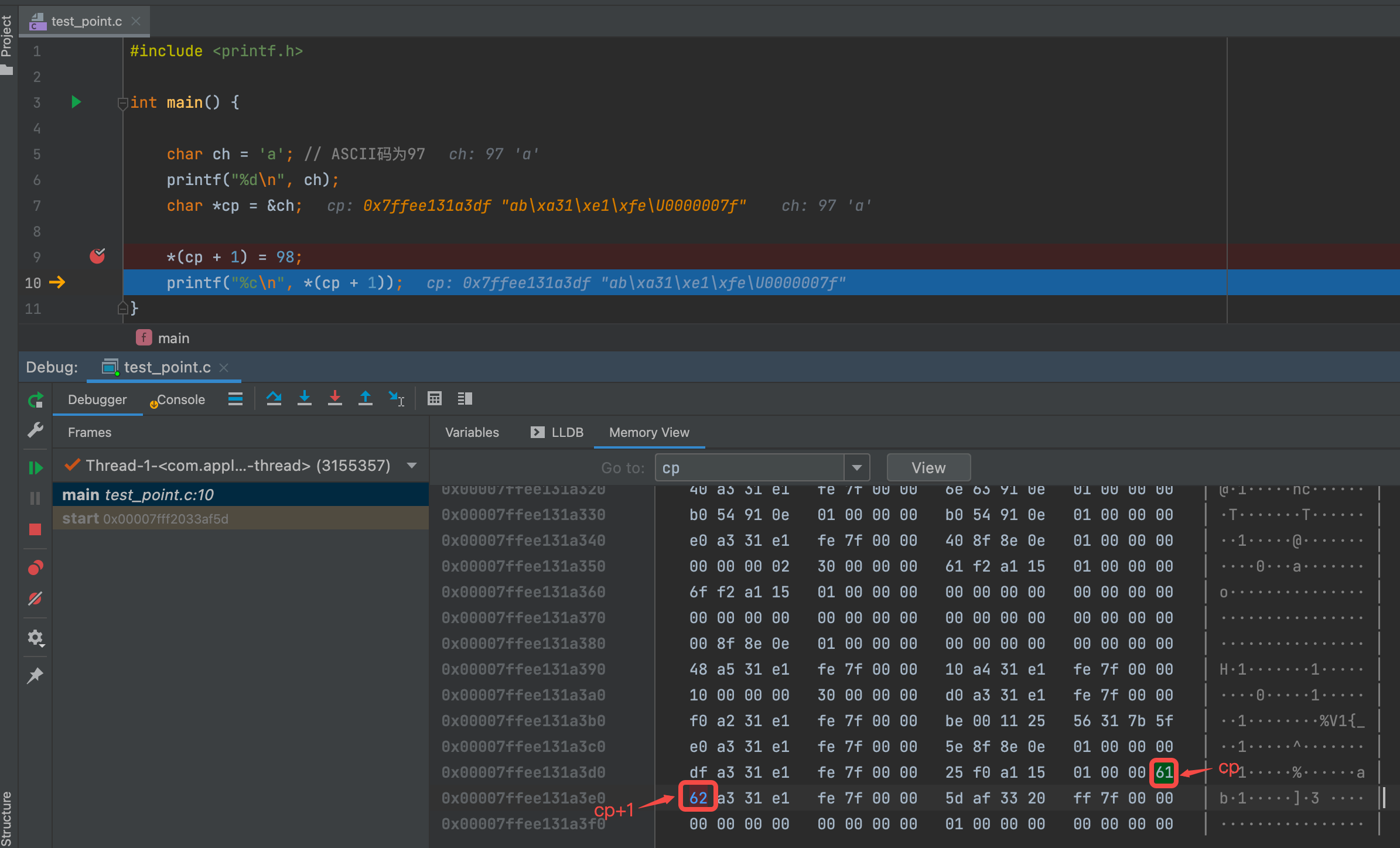
表达式
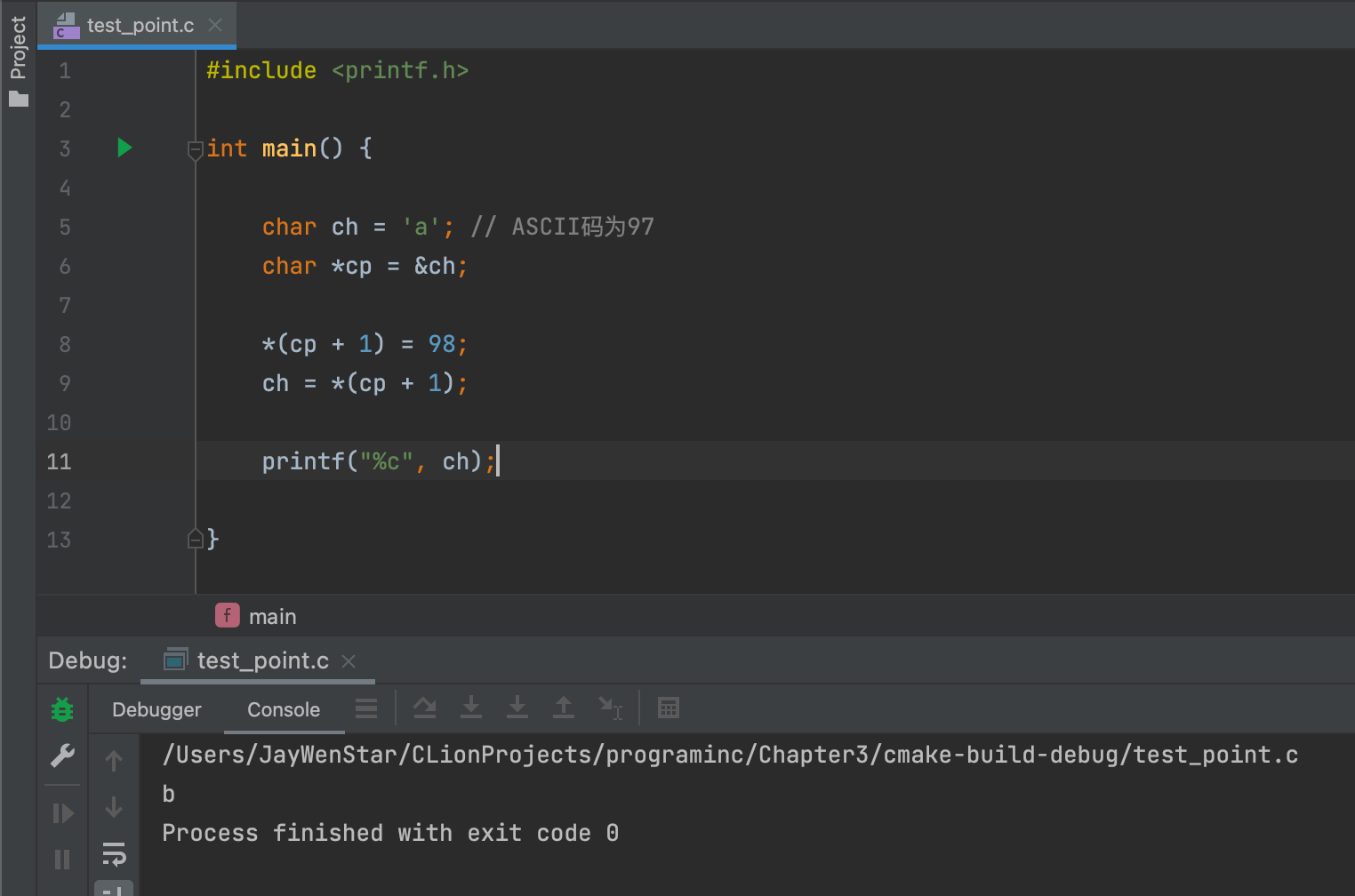
*(cp + 1)- 左值 ✅:
*(cp + 1) = 98成立,含义为对cp地址的后一位设置为62(98的16进制)。 - 右值 ✅:
ch = *(cp + 1)成立,含义为将cp地址后一位的内容赋予变量ch。 - 左值例子👇🏻:
- 右值例子👇🏻:
- 左值 ✅:
从这里开始注意,但凡有++的,返回的都是拷贝指针,以下文字中可能会省略
-
表达式
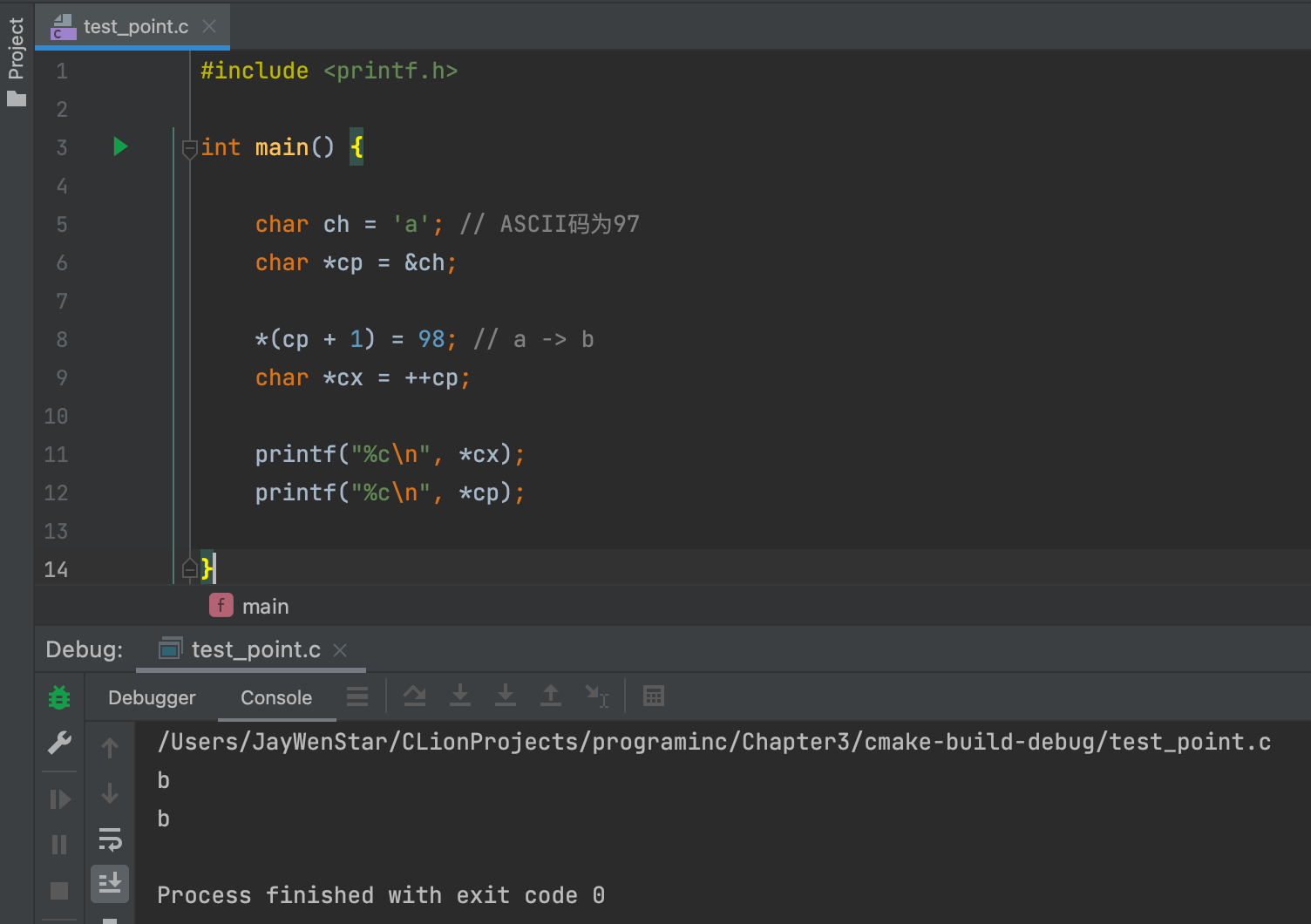
++cp- 左值 ❌:
++cp = 任何不成立。 - 右值 ✅:
char *cx = ++cp成立,含义为cp指针的地址指向后一位,并把新指针赋值给*cx。 - 右值例子👇🏻:
- 可以在
char *cx = ++cp后加一行--cp,cp的输出结果会变成a,但cx依旧是b,证明cx不是指向cp。
- 左值 ❌:
-
表达式
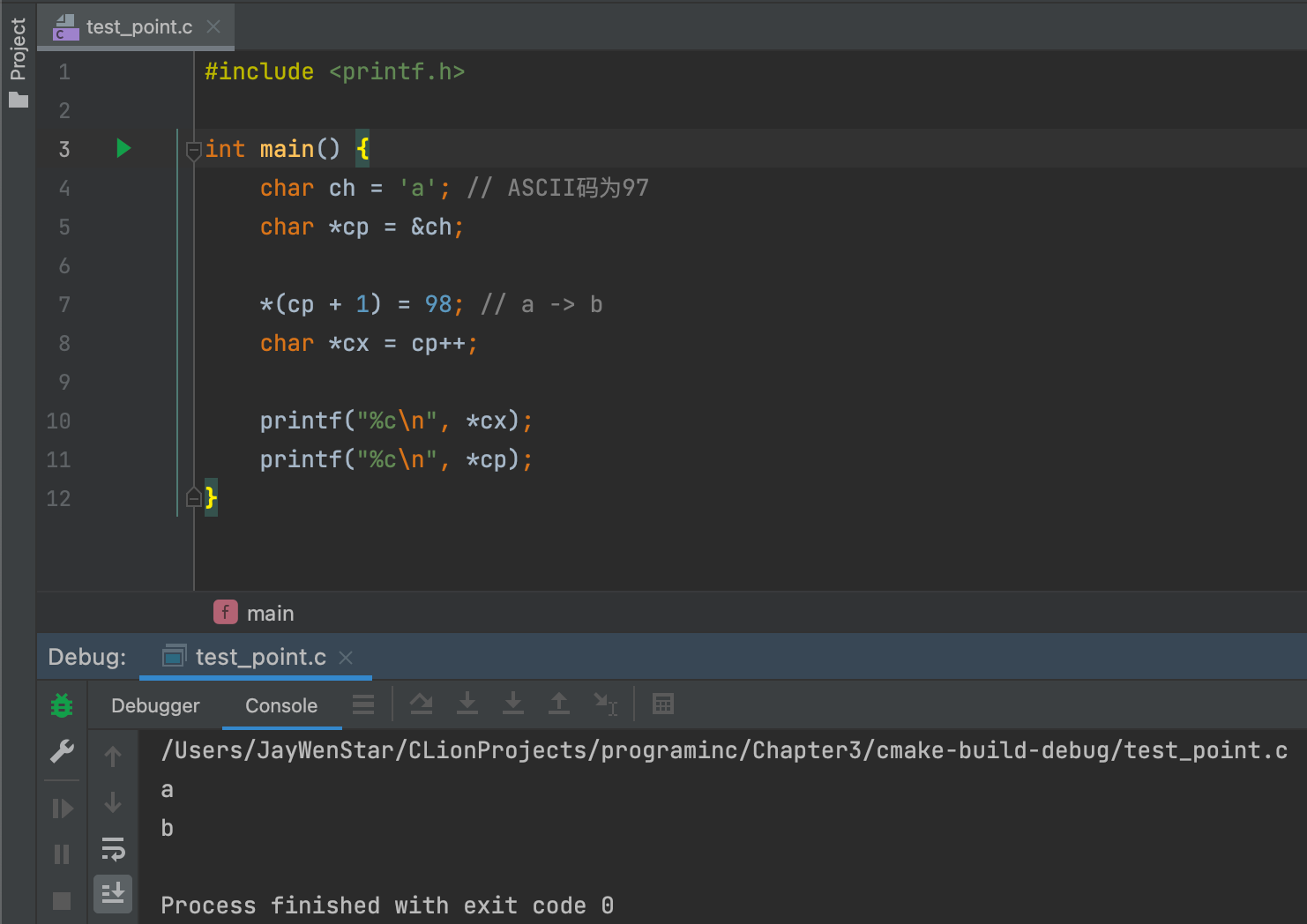
cp++- 左值 ❌:
cp++ = 任何不成立。 - 右值 ✅:
char *cx = cp++成立,含义为先把cp的指针赋予*cx,然后cp地址指向后一位。 - 右值例子👇🏻:
- 同样可以在
char *cx = cp++后加一行--cp,*cp的结果变成a,*cx依旧是a,证明cx不是指向cp。
- 左值 ❌:
-
表达式
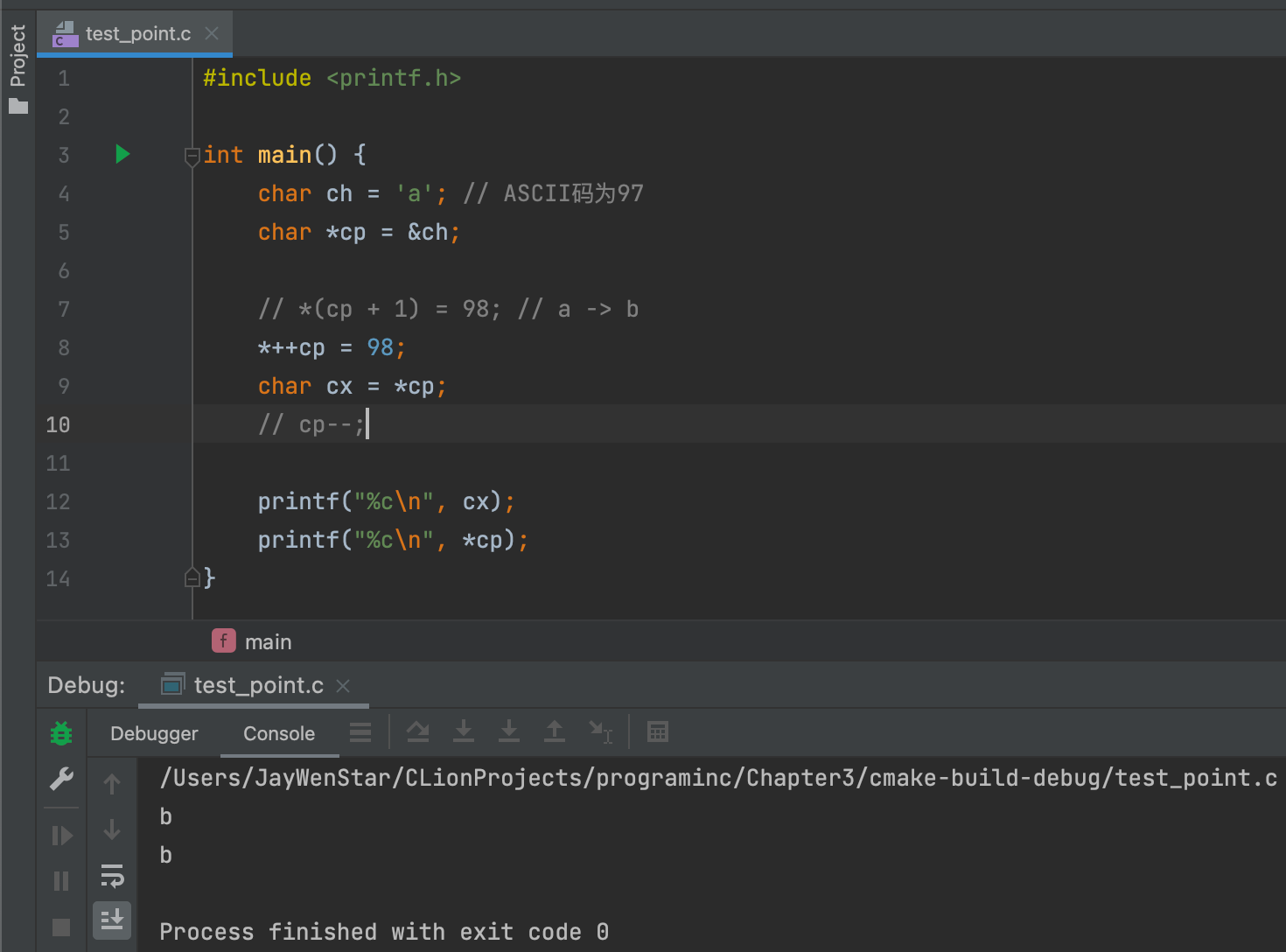
*++cp- 左值 ✅:
*++cp = 98成立,含义就是把cp的地址指向后一位,然后把98放到在这个地址。 - 右值 ✅:
char cx = *++cp成立,++cp是返回地址,而在前面加个*就是把地址的值返回。 - 左值例子👇🏻:
- 同样的把
cp--注释去掉,cp会变成a,cx依旧不变,证明cx不是指向cp。 - 右值例子👇🏻:
- 左值 ✅:
-
表达式
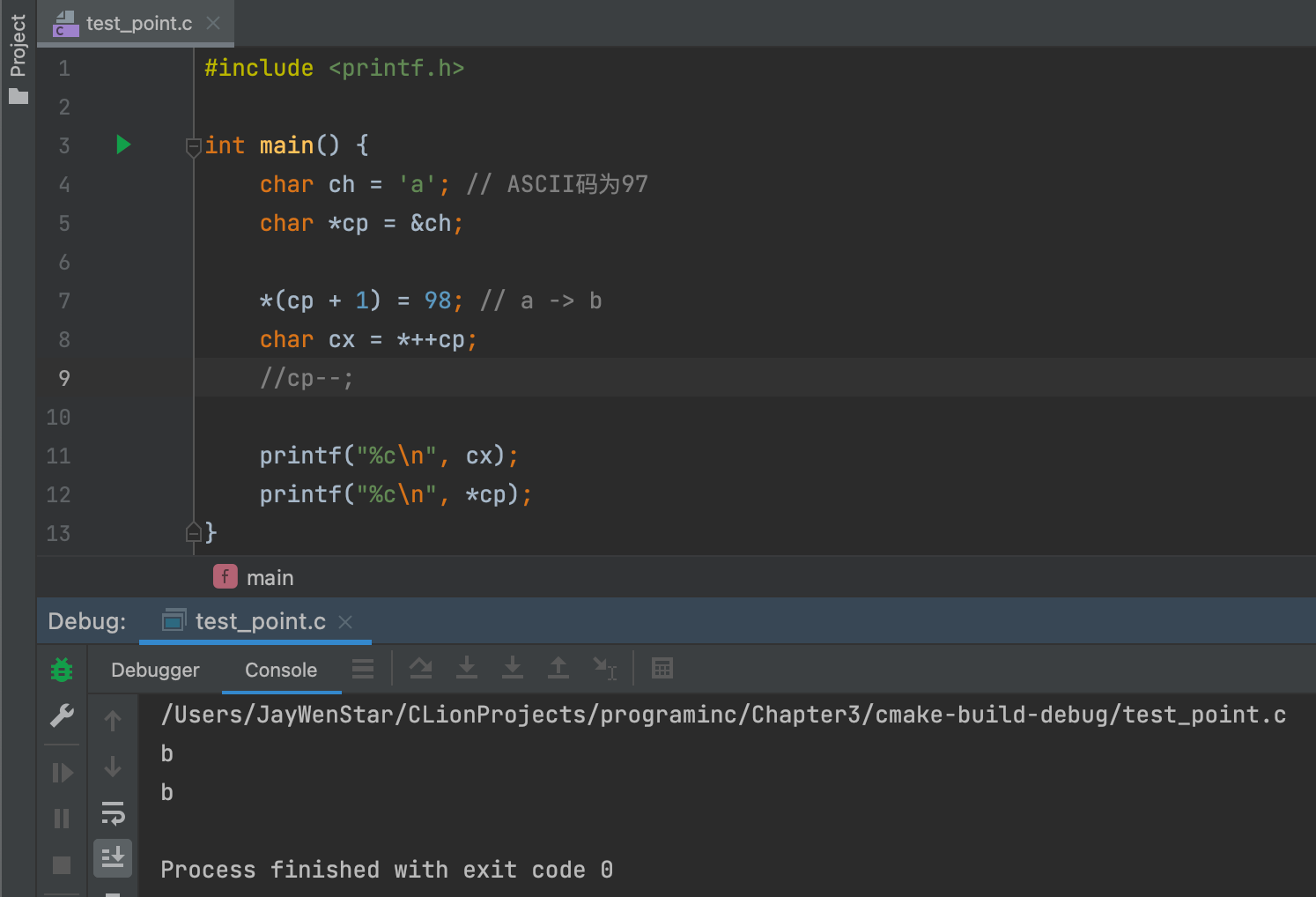
*cp++- 左值 ✅:
*cp++ = 98;成立,内部逻辑:①++操作符产生cp值的拷贝;②cp指针指向下一位;③将98放到①中的拷贝地址。从结果看很容易误会成先执行*再++,但实际上不是。 - 右值 ✅:
char cx = *cp++;成立,内部逻辑除了赋值,跟上面基本相同。 - 左值例子👇🏻:
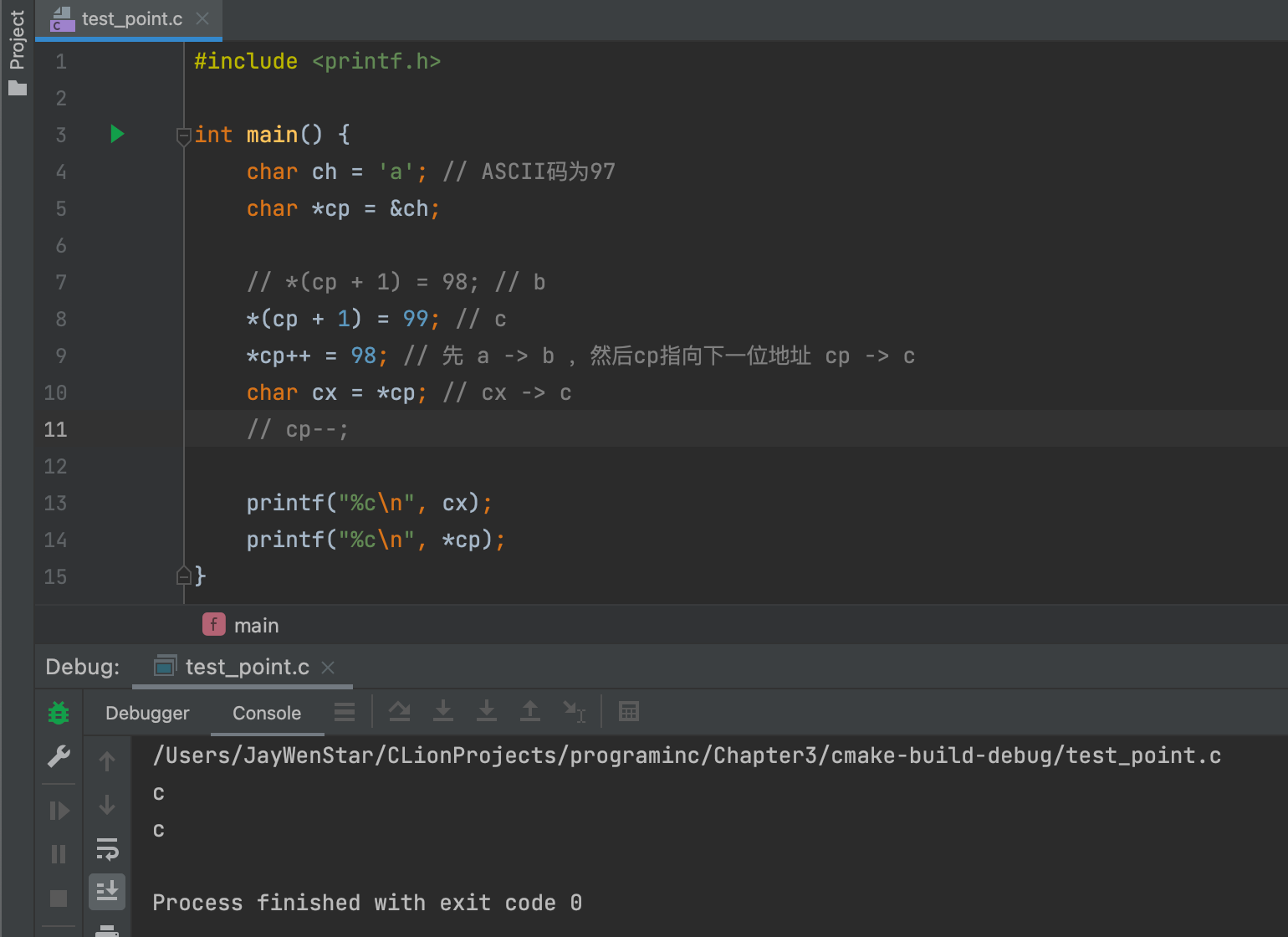
- 把
cp--注释去掉,则cp=b,cx依旧为c。 - 右值例子👇🏻:
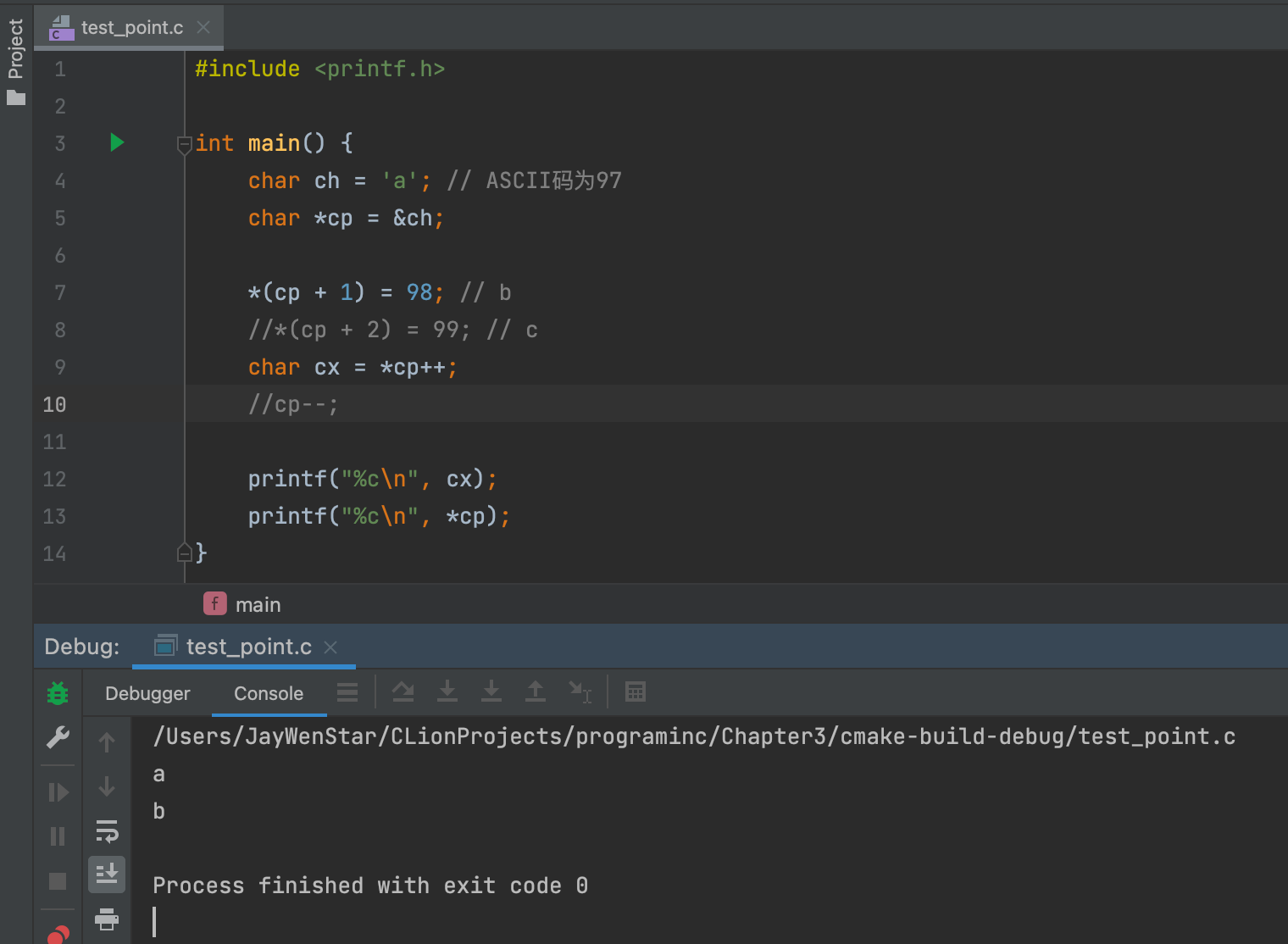
- 把
cp--注释掉后,cp也会变成a,cx依旧为a。
- 左值 ✅:
-
表达式
++*cp- 左值 ❌:
++*cp = 任何不成立。 - 右值 ✅:
char cx = ++*cp成立,转化下就是char cx = ++*&ch = ++ch,最终ch为b,赋值给cx。 - 右值例子👇🏻:
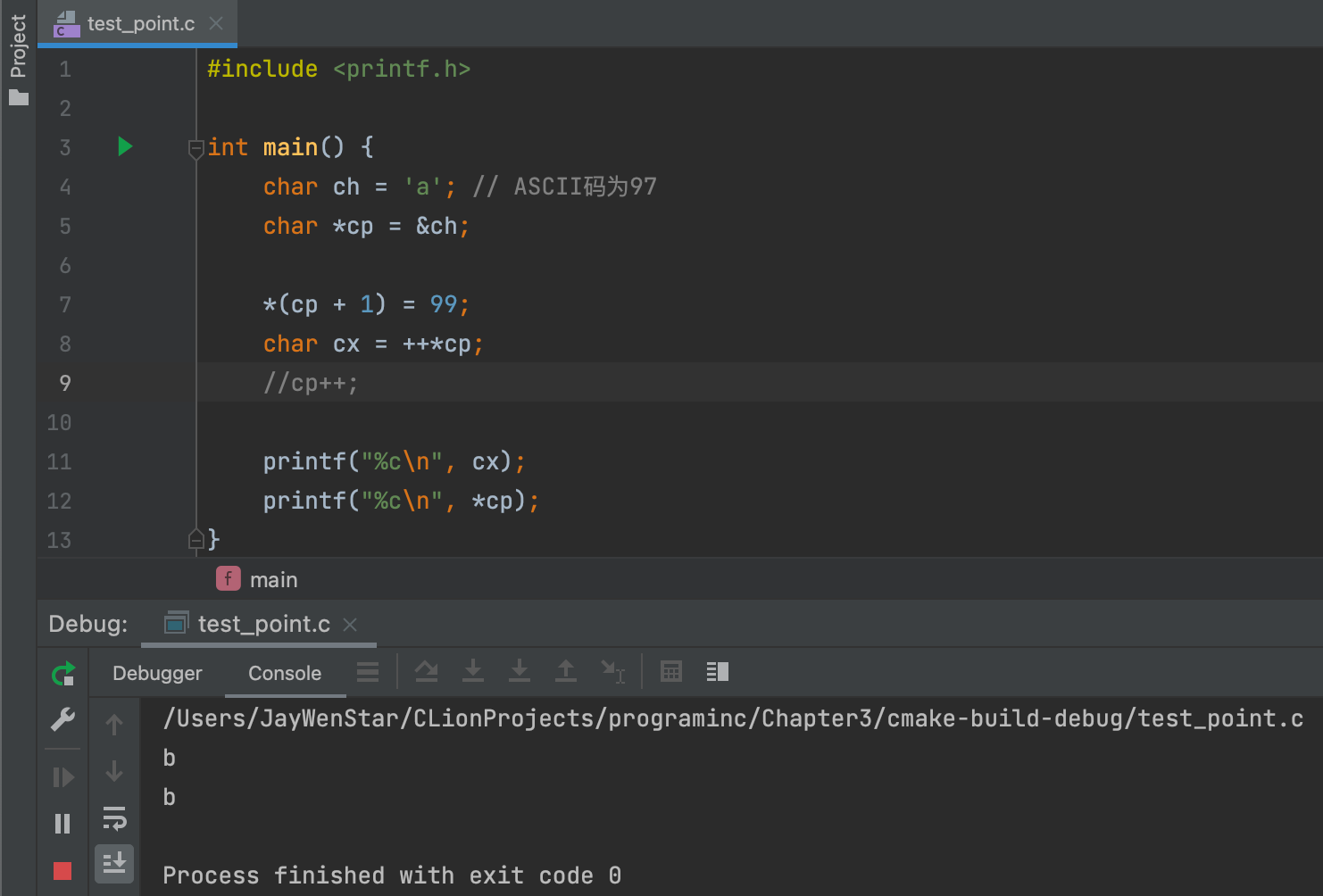
- 如果把cp++注释去掉则,cp为c,cx为b,证明cx不是指向cp。
- 左值 ❌:
-
表达式
(*cp)++- 左值 ❌:
(*cp)++不成立。 - 右值 ✅:
char cx = (*cp)++;成立,跟*cp++不同,这里是先取cp地址的值,然后再++(作用于原来的地址,也就是把a改成b),不会改变指针位置。 - 右值例子👇🏻:
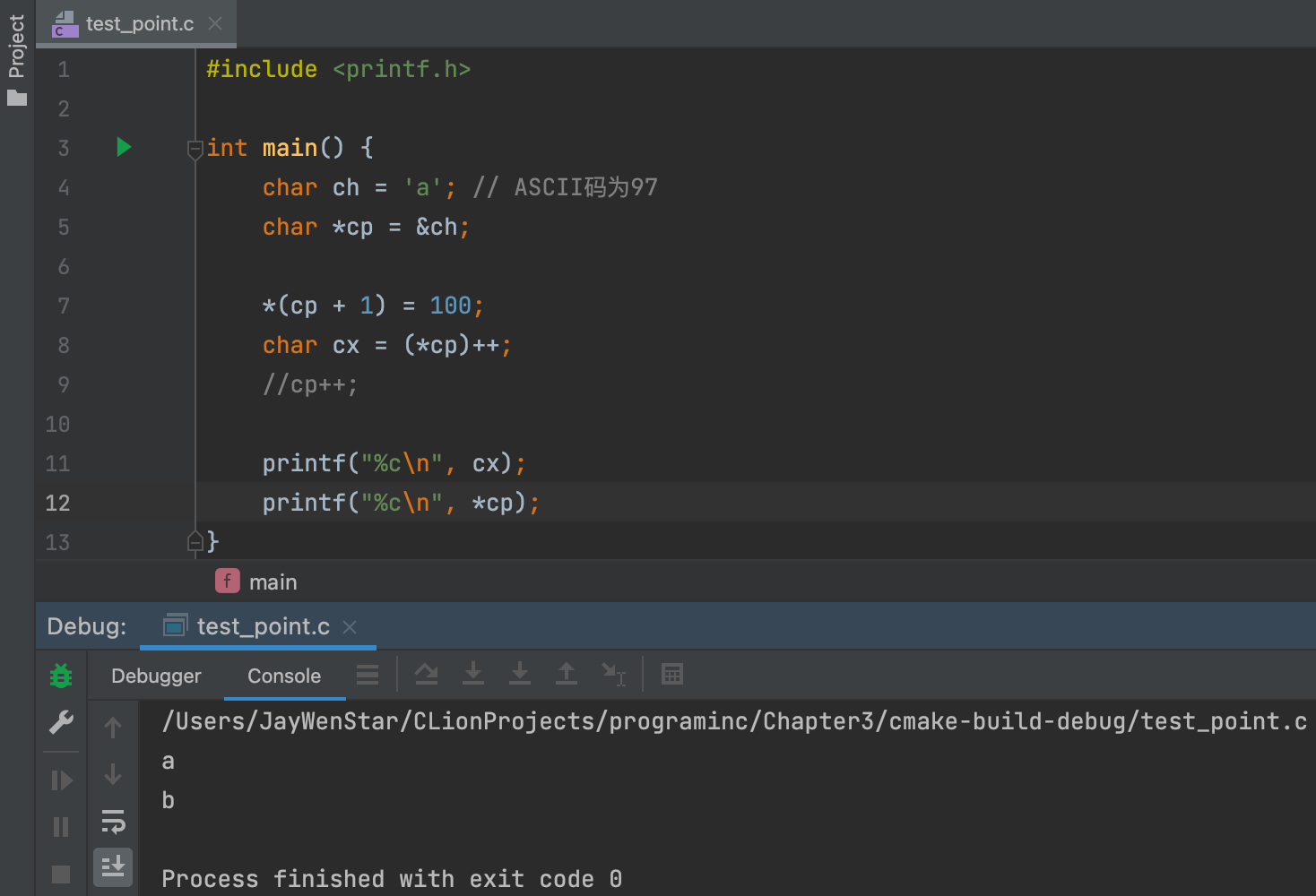
- 如果把
cp++注释去掉,那么cp为d,cx为a。
- 左值 ❌:
-
表达式
++*++cp- 左值 ❌:
++*++cp = 任何不成立。 - 右值 ✅:
char cx = ++*++cp;成立,从右到左看,*++cp是把cp地址指向后一位,然后取出当前地址的值;取出值为b,然后执行++b=c,当前地址的b被改成c了。 - 右值例子👇🏻:
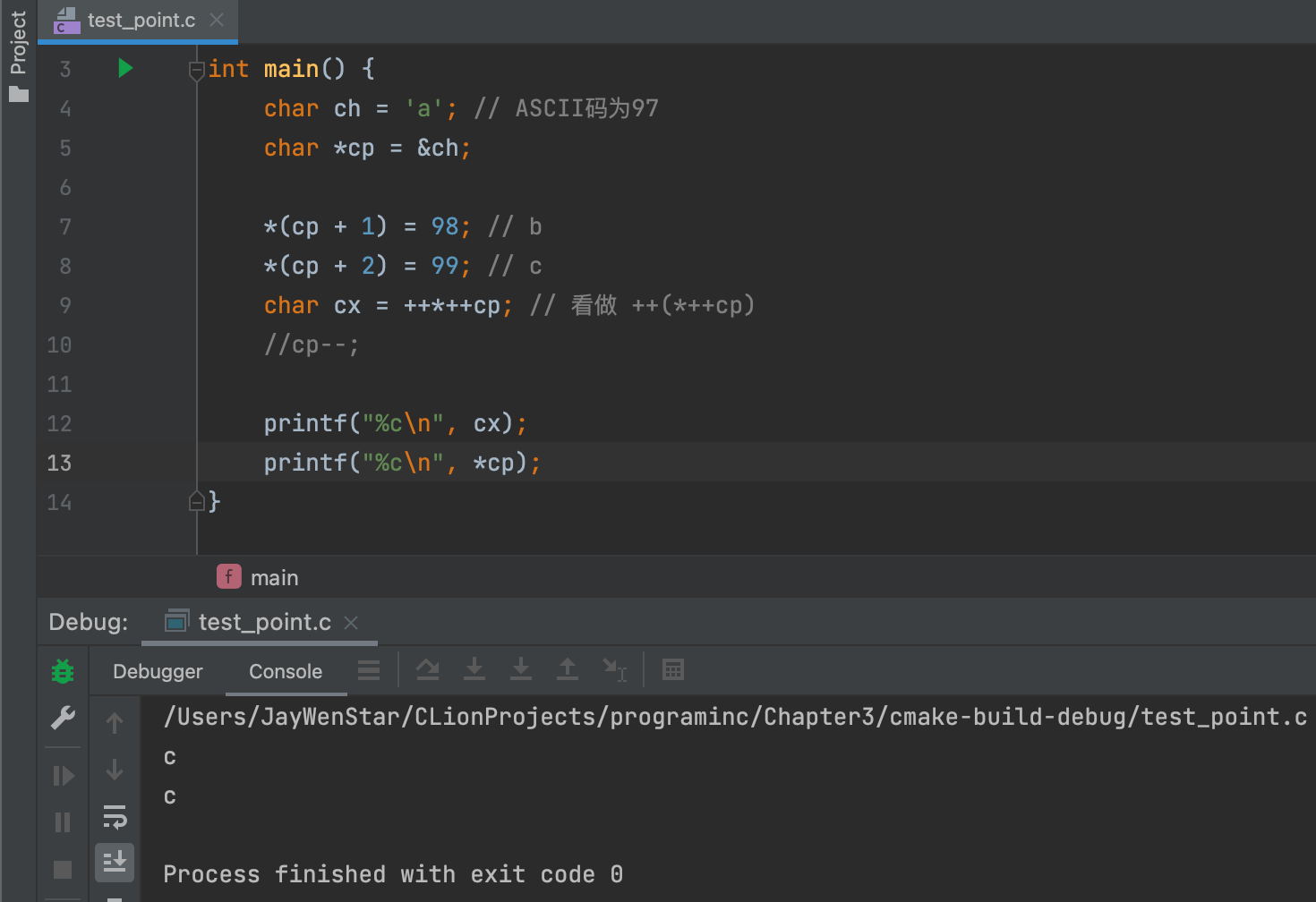
- 注意这里*(cp + 1)已经被改成c了,所以把cp–注释掉后,cp为a。
- 左值 ❌:
-
表达式
++*cp++- 左值 ❌:
++*cp++ = 任何不成立。 - 右值 ✅:
char cx = ++*cp++;成立,这里的含义有些复杂,首先会把*cp的值给前面的加号,得到结果为b,赋予cx(cx=b);之后再执行cp++,把cp指向后一位地址。 - 右值例子👇🏻:
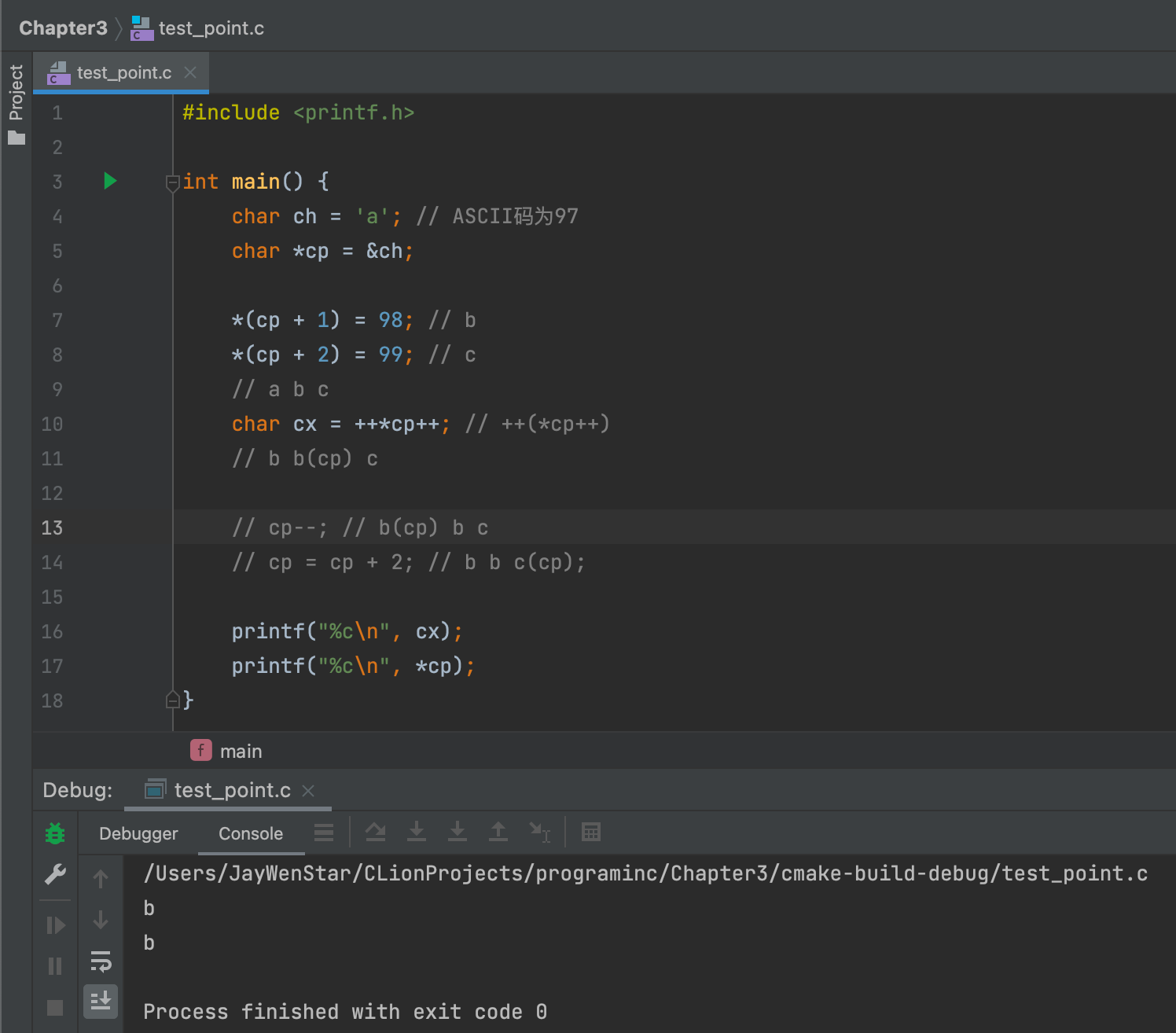
- 如果把
cp--注释去掉,则cp为b,如果在此基础上把cp = cp + 2注释去掉,那么cb就为c。
- 左值 ❌:
好了,基础的算式先记到这里,实际上后面还有数组算式等各种各样的初见杀,等之后有时间再一一补上了。
指针-一维数组
让我们来看看如下代码👇🏻:
#include "stdio.h"
#define SIZE 7
int main() {
char chars[SIZE] = {'a', 'b', 'c', 'd', 'e', 'f', 'g'};
char *ptr1 = chars;
char *str = "abcdefg";
for (int i = 0; i < SIZE; i++) {
printf("%c", *(ptr1 + i));
}
puts("");
for (int i = 0; i < SIZE; i++) {
printf("%c", *(str + i));
}
puts("");
return 0;
}
// 输出结果👇🏻
abcdefg
abcdefg
根据以上程序的结果,我们可以得知chars[i] = *(chars + i) = *(ptr1 + i),这是因为数组的内存是连续的,无论是下标还是其它方式都是根据内存偏移的方式获取值的,所以最终结果都是相同的。
除此之外,指向一维数组的指针还有如下等式:
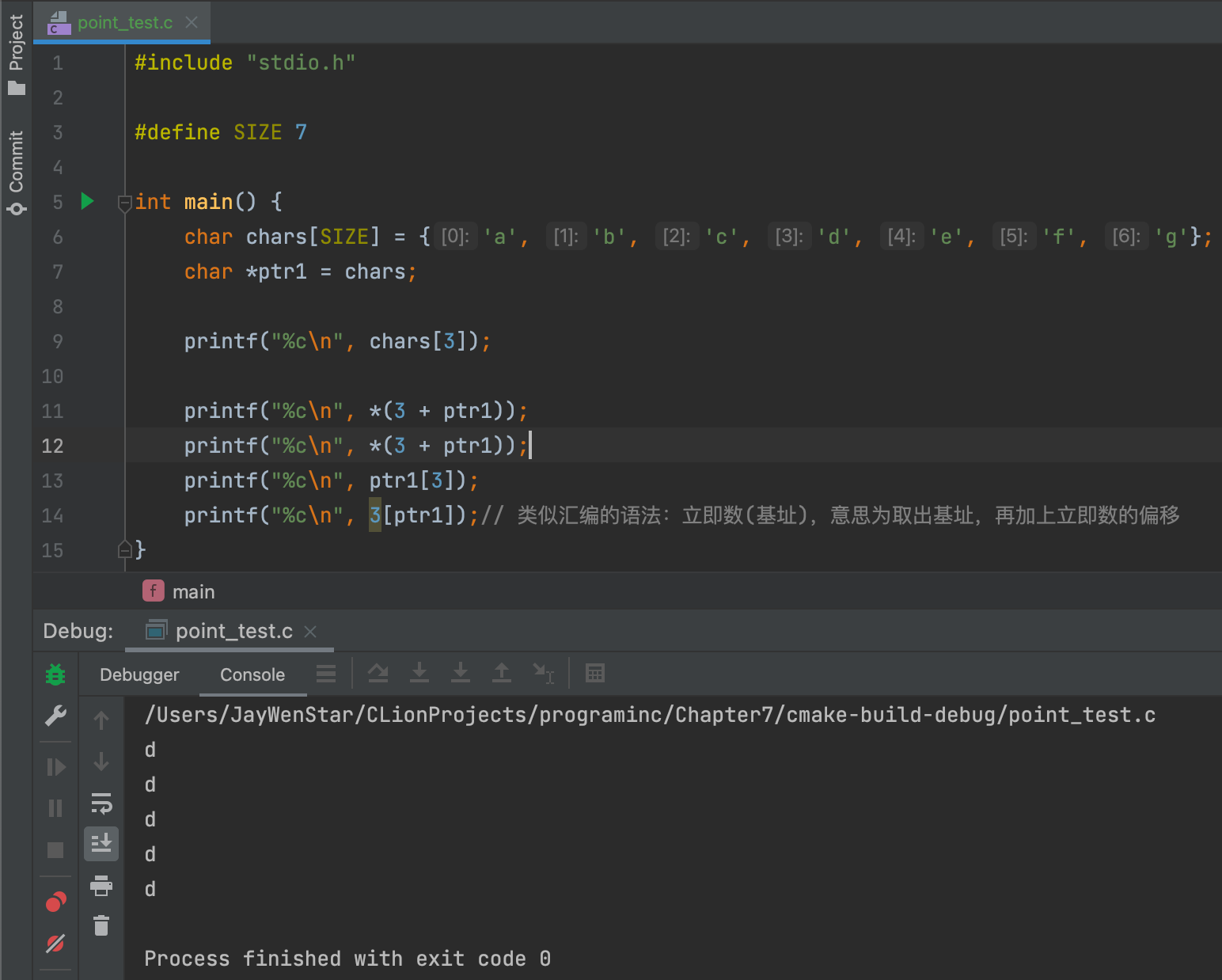
指针-多维数组
这里就拿二维数组做实验,代码如下:
#include "stdio.h"
#define SIZE 4
int main() {
char chars[SIZE][SIZE] = {
{'q', 'w', 'e', 'r'},
{'a', 's', 'd', 'f'},
{'z', 'x', 'c', 'v'},
{'u', 'j', 'n', 'l'}
};
char *ptr = chars; // 实际上已经指向了char[0][0]的位置,所以无法像chars一样直接根据数组大小偏移直接"跳行"
puts("chars首字母遍历:");
for (int i = 0; i < SIZE; i++) {
printf("%c\n", *(*(chars + i) + 0));// 等效于chars[i][0]
}
puts("");
puts("chars第二字母遍历:");
for (int i = 0; i < SIZE; i++) {
printf("%c\n", *(*(chars + i) + 1));// 等效于chars[i][1]
}
puts("");
puts("一些等式");
printf("%c\n", chars[2][2]);
printf("%c\n", *(*(chars + 2) + 2));
printf("%c\n", *(ptr + 10));
return 0;
}
输出结果如下:
chars首字母遍历:
q
a
z
u
chars第二字母遍历:
w
s
x
j
一些等式
c
c
c
指针的数组和数组的指针
这里代码换成C++,但除了输出代码外,实际上用的还是C风格的代码
- 这里引入另一个概念:数组
[]结合的优先级高于指针*。直接说有点抽象,看完下面的解析就懂了。 - 代码、注释如下:
#include <iostream>
using namespace std;
int main()
{
// array of pointers和a pointer to an array
int c[4] = { 1, 2, 3, 4 };
// array of pointers-指针的数组
int* a[4];
int(*b)[4]; // a pointer to an array 数组的指针
b = &c; // 注意:这里数组个数得匹配
// 将数组c中元素赋给数组a
for (unsigned int i = 0; i<4; i++)
{
a[i] = &(c[i]);
}
cout << *(a[0]) << endl; // 1
cout << (*b)[3] << endl; // 4
cout << b << endl; // 数组首位的地址
cout << b[0] << endl; // 数组首位的地址
return 0;
}
- 你可能会比较疑惑a、b的表现,先看看ide断点中,a、b、c的数据类型:

- 首先是a,
int *[4]中首先是*[4]先结合,再跟int结合,可以理解为int (*[4]),表示指向一个一维且大小为4的指针数组(数组存储的是地址而非值);另外,可以看到a中第一个元素的内存地址才等于b、c的地址: 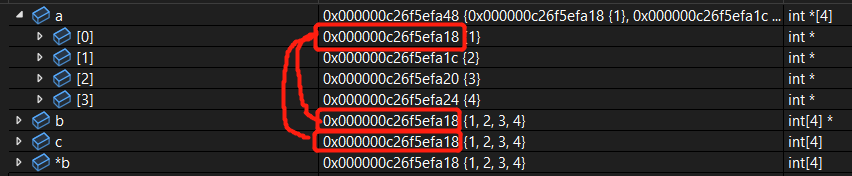
- 接下来是b,
int[4] *中首先是int[4]先结合,再跟*结合,可以理解为(int[4])*,表示指向一个一维大小为4的指针,虽然从debug的值看不出b、c的区别,但实际上,b是一个地址,跟上面a的第一个元素地址一样,这个地址就是c[0]的地址,我们可以看下最终的打印结果: 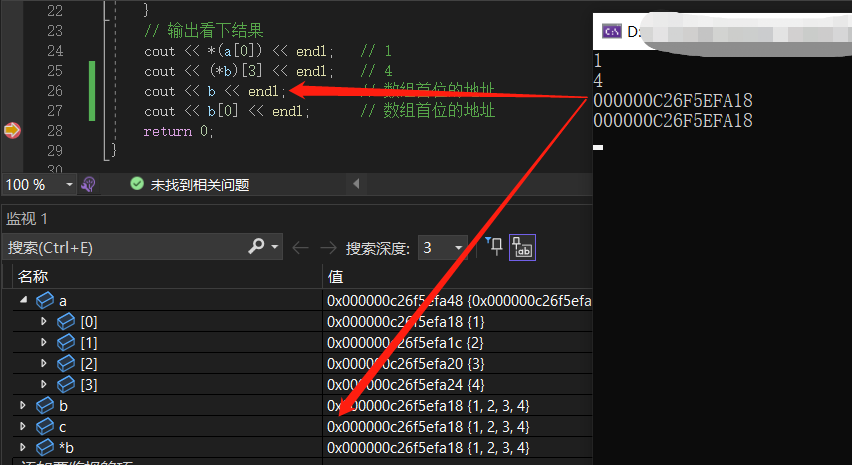
- 首先是a,
指针常量
《C与指针》第8章中提到过,数组变量本质上就是指向某个类型的常量指针,比如char chars[1] = {'a'};就是指向char类型的常量指针
下面附上一个常量指针例子的代码(注释含解释):
#include <stdio.h>
#include <io_utils.h>
int main() {
int a = 20;
int b = 99;
int *p = &a;
PRINT_INT(*p);
PRINT_INT(a);
// 从右往左看,一个只读指针(*const)指向一个整形变量(int)
// 因为const只用来修饰指针,所以指针指向的地址不可变,但地址的值可变(int不受约束)
int *const cp = &a;
*cp = 2; // OK
//cp = &b; // ERROR
// 一个指针(*)指向只读变量int(int const)
// const只修饰int,指针无修饰,所以不能修改值(int),但是指针是自由的,所以能被修改
int const * cp2 = &a;
// *cp2 = 2; ERROR
cp2 = &b; // OK
// 一个只读指针(*const)指向一个只读的int变量(int const)
// 从右到左第一个const既作用于指针,第二个const作用于int,所以 只读指针+只读变量 都不可以修改
int const *const ccp = &a;
// ccp = &b; ERROR
//*ccp = 2; ERROR
return 0;
}
C的volatile关键字
- C标准中的
volatile并不像Java那样能保证可见性(但MSVC可以)。 - 它的作用是禁止编译器优化被修饰的元素。
- 理所当然的也不保证原子性。
C的继承与多态
众所周知,在C里面没有类、继承等关键字,但却依旧有继承的概念。C的继承跟Go有些类似,是使用包装实现的继承。
多说无益,直接看下面一个包含继承、强转(多态)代码例子👇🏻:
#include <stdio.h>
struct Creature {
char const *name;
int age;
void (*print) (struct Creature *);
};
typedef void (* printName) (struct Creature *);
void print(struct Creature * creature) {
printf("%s\n", creature->name);
}
struct Creature newCreature() {
struct Creature creature = {.print=print, .name="Creature"};
return creature;
}
struct Human {
struct Creature parent_class;
char const *address;
int gender;
void (*print) (struct Human *);
};
struct Human newHuman() {
struct Human human = {.parent_class=newCreature()};
human.print=(void *)human.parent_class.print;
human.parent_class.name="Human";
return human;
}
struct Student {
struct Human parent_class;
char const *student_number;
char const *school;
void (*print) (struct Student *);
};
struct Student newStudent() {
struct Student student = {.parent_class=newHuman()};
student.print=(void *)student.parent_class.print;
student.parent_class.parent_class.name = "Student";
return student;
}
int main() {
// 整体继承关系:Student 继承 Human 继承 Creature
struct Creature creature = newCreature();
struct Human human = newHuman();
struct Student student = newStudent();
puts("调用各print函数");
creature.print(&creature);
human.print(&human);
student.print(&student);
puts("");
puts("\"父类\"强转\"子类\":");
struct Human *forceHuman = (struct Human *) &creature;
// forceHuman->print(forceHuman); // 虽然强转了,但此Human实例的print指针是空的,所以这里调用不会有任何反应
printf("%s\n", forceHuman->parent_class.name);
printf("父类结构体大小:%lu\n", sizeof(creature));
printf("子类结构体大小:%lu\n", sizeof(*forceHuman)); // 去掉*就是指针大小,64位机器上通常固定8字节,32位4字节
puts("");
puts("\"子类\"强转\"父类\":");
struct Creature *forceCreature = (struct Creature *) &student;
forceCreature->print(forceCreature);
printf("父类结构体大小:%lu\n", sizeof(student));
printf("子类结构体大小:%lu\n", sizeof(*forceCreature)); // 去掉*就是指针大小,64位机器上通常固定8字节,32位4字节
puts("");
return 0;
}
输出结果如下👇🏻:
调用各print函数
Creature
Human
Student
"父类"强转"子类":
Creature
父类结构体大小:24
子类结构体大小:48
"子类"强转"父类":
Student
父类结构体大小:72
子类结构体大小:24
你可能会好奇为啥C能做到这一点,其实这都得益于结构体内存对齐,拿父类转子类来说,其实就是创建一个子类的指针,然后指向父类即可,如下图所示👇🏻:
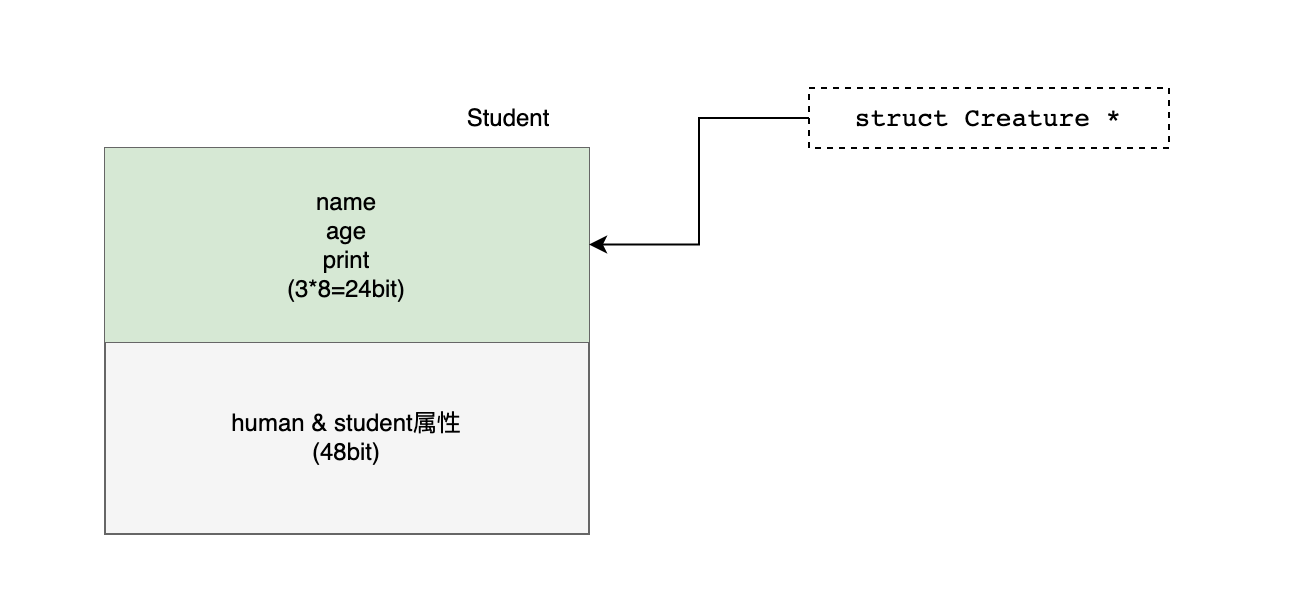
- 因为内存对齐的缘故,当指针指向父类时,刚好可以完整获取到对应范围的内存,于是看起来就强转成功了。
- 另外,也由于内存对齐的缘故,如果父类没有声明在结构体的第一行,那也会翻车,有点类似于Java中
super()必须写在第一行(当然我不确定Java这么做的原因是不是因为内存对齐)