前言
前段时间在写一个小项目bbs模块时,遇到一个小小的困难,那就是如何更高效的加载帖子下的评论、回复内容。如果纯写SQL的话,总感觉是个小噩梦,于是我就想能不能用业务JOIN的方法替代写SQL,最好能发挥出比纯SQL更高的性能。
好巧不巧,受到前几天某个面试题的影响,于是就写出了这次的业务JOIN。
面试题是这样的:
- Q:对比
B+树和Hash表它们各自有什么优缺点呢? - A:答案就不细说了,主要从范围查找,Hash冲突等点回答。
PS: 每次回忆面试都相当痛苦,比如面试官问的HashMap的hash冲突如何解决,但我紧张起来就把问题截断成:hash冲突如何解决,然后就只反应到拉链法。事后总感觉到这个问题很奇怪,原来发现自己听漏了。。真的佛了自己
场景
为了能清晰地表达我所面临的问题,我先画一张界面的草图(前端在努力肝了):
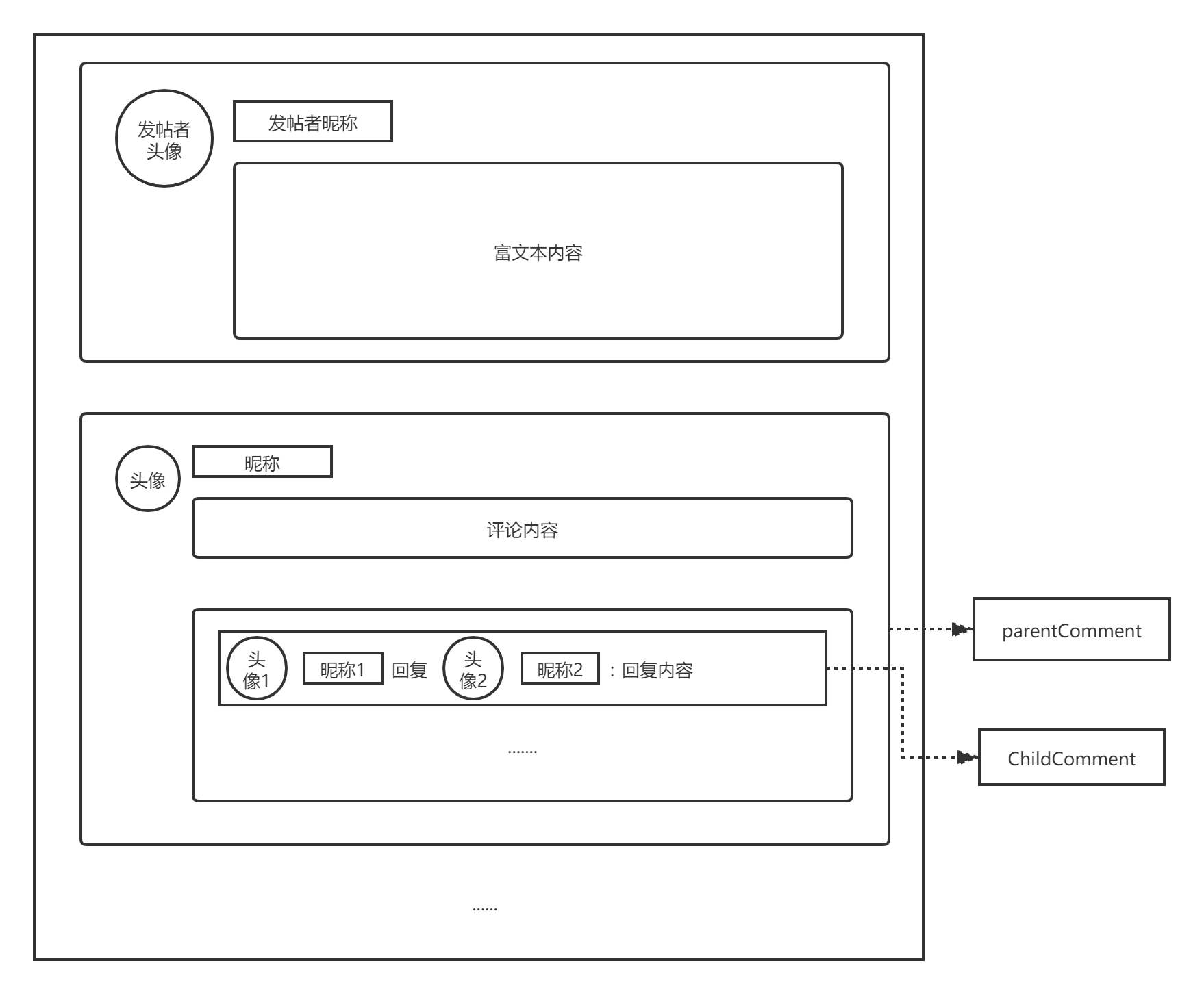
- 其实和平时用的百度贴吧,又或者是B站的评论结构差不多。
parentComment就称为父评论吧,childComment称为子评论。
为了后面的代码逻辑能更清晰,再贴下数据库表大概长啥样:
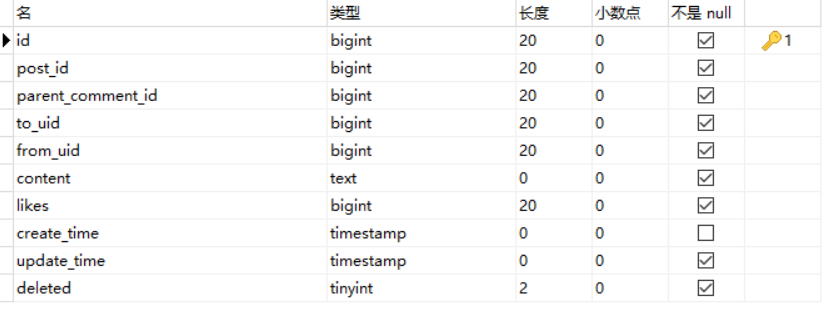
- parent_comment_id:若值为0,则就是父评论;若值为父评论id,则是父评论下的子评论。
现在,我们需要查询某一分页的所有评论数据,这里的难点主要在于如何高效查询用户的头像、昵称信息,因为除了父评论之外,每条子评论都需要查询用户头像、昵称。
如果单纯使用SQL的话,好一点的方案就是创建临时表JOIN,坏一点的方案就是房放飞自我的笛卡尔积。然而无论是哪种,我个人都觉得操作比较复杂且难以维护,于是我就决定自己实现业务JOIN。
业务JOIN的实现
为了提高用户信息的查询的效率,我选择把查询出的父评论,或父评论下子评论集合的uid都保存到Set中,然后用in范围条件一次性查询出所有uid对应的用户信息(头像、昵称),然后把查出来的结果以<uid, User>转为HashMap存储,之后无论是父评论还是子评论,都直接拿uid去HashMap中取出用户信息填充即可。
具体代码实现如下(上面的说明对比下面的代码依旧省略了一些细节):
@Override
public Page<PostComments> listParentCommentsByPostId(Page<PostComments> page, Long postId) {
return page(page, new QueryWrapper<PostComments>()
.eq("post_id", postId)
.eq("parent_comment_id", 0)
.orderByDesc("likes"));
}
@Override
public CommentPage<ParentCommentVO> listCommentOfPost(Page<PostComments> page, Long postId, Long operatorUid) {
// list parent comments
Page<PostComments> postCommentsPage = listParentCommentsByPostId(page, postId);
long total = postCommentsPage.getTotal();
Set<Long> uids = new HashSet<>(1 << 8);
List<Long> parentCommentIds = new ArrayList<>();
List<ParentCommentVO> parentCommentVOList = postCommentsPage.getRecords()
.stream().map(e -> {
uids.add(e.getFromUid());
parentCommentIds.add(e.getId());
return (ParentCommentVO) new ParentCommentVO().convertFrom(e);
}).collect(Collectors.toList());
if (postCommentsPage.getTotal() == 0) {
return new CommentPage<>(total, new ArrayList<>());
}
// list child comments
List<PostComments> childComment = list(new QueryWrapper<PostComments>()
.in("parent_comment_id", parentCommentIds).orderByDesc("create_time"));
List<ChildCommentVO> childCommentVOList = childComment.stream().map(e ->
BeanUtils.transformFrom(e, ChildCommentVO.class)).collect(Collectors.toList());
// group by parentCommentId
Map<Long, List<ChildCommentVO>> childCommentMap = childCommentVOList.stream().collect(Collectors.groupingBy(ChildCommentVO::getParentCommentId));
childCommentMap.forEach((k, v) -> {
v.forEach(e -> {
uids.add(e.getFromUid());
uids.add(e.getToUid());
e.setLikes(getCommentLikeCount(e.getId()))
.setLike(isLikeComment(operatorUid, e.getId()));
});
});
// list user and then transform map
Map<Long, User> userHashMap = userService.listByIds(uids).stream().collect(Collectors.toMap(User::getUid, e -> e));
users.forEach(e -> userHashMap.put(e.getUid(), e));
// set nickname、avatar、child comments and so on.
childCommentMap.forEach((k, v) -> {
v.forEach(e -> {
User fromUser = userHashMap.get(e.getFromUid());
User toUser = userHashMap.get(e.getToUid());
e.setFromNickname(fromUser.getNickname())
.setToNickname(toUser.getNickname())
.setFromAvatar(fromUser.getAvatar());
});
});
parentCommentVOList.forEach(e -> {
User user = userHashMap.get(e.getFromUid());
e.setNickname(user.getNickname())
.setAvatar(user.getAvatar())
.setLikes(getCommentLikeCount(e.getId()))
.setLike(isLikeComment(operatorUid, e.getId()))
.setChildComments(childCommentMap.get(e.getId()));
});
return new CommentPage<>(postCommentsPage.getTotal(), parentCommentVOList);
}
- 如果你为了保证某种一致性、原子性,需要控制SQL的可见性,那么不要忘记额外控制事务隔离级别哦~
总而言之,核心思路就是HashMap保存一些临时的结果集、手动用Java代码,需要的时候就从里面取出,这个样子就可以一定程度上取代纯SQL操作,在某些场景下有可能取得更高的性能。