前言
前段时间在做课程设计的时候,有一个需求是【用户支付后系统自动分配配送员,且保证订单能平均配分】,而我使用了RocketMQ + Redis实现了这个功能,所以本篇就来简单聊一聊我为什么这么做?这么做的好/坏处在哪?
PS:"保证订单能平均分配"中的保证,我理解成了强保证,即整个过程要保证原子性。
关于软保证,我会在文末提一下,但事先说明下软保证比强保证要简单。
2020年5月2号补充:Redis 新版6.x开始正式支持多线程了。
分析需求
其实这需求咋一看,实现起来非常简单,比如可能有人想到如下方案:
- 可以在数据库表中存储配送员的 id 和 权重,每次支付完后,取权重最高的配送员id + 减少权重,完成分配。
- 每次支付完后,查询所有配送员当前正在配送的任务数量,取最低任务数量的配送员id,完成分配。(妈见打系列)
- 应用启动时加载配送员数据到ConcurrentSkipListSet/TreeSet(注意线程安全),每次支付后,从中取权重最高的配送员id + 减少权重,完成分配。
- 使用Redis的zset存储配送员的权重和id,每次支付后,从中取出权重最高的配送员id + 减少权重,完成分配。
对于第一种方式,可以实现,但性能不高,因为要扫全表。
对于第二种方式,可以实现,但是性能妈见打。
对于第三种方式,可以实现,性能不错,但编码工作量高(如需持久化得自己编写),出现问题也不容易排查。
对于第四种方式,可以实现,性能不错,编码量少,出现问题也相对容易排查。
在最后,显而易见,我选择了第四种方式。
那选择第四种方式之后,是不是就可以开始撸代码了呢?
答:可以,但是还能继续优化。
进一步优化
不足之处:
如果说我们的目的只是为了取到当前任务量最少的配送员id,那么上面的想法大可及格。
但很遗憾,在取出配送员id前后,我们的系统还有一系列操作,比如用户支付后,我们首先要将订单的状态更改为【已支付】,然后再取出任务量最少的配送员,之后再将配送员id更新到表中。
假如现在表的数据量比较大,而且请求也比较多,而这三个步骤都放在用户一次请求中同步执行,那系统的并发量就会受到很大的限制。
想法改进:
既然现在知道了不足的地方,那么应该怎么优化呢?
首先,我们要回到现实中重新理一理思路,给的需求是支付后分配配送员,但并没有强调支付后马上分配配送员。
然后,根据这一点,我脑海里出现了一个词:最终一致性。
试想一下自己平时用的快递APP,下单后虽然是马上分配配送员了,但是配送员一般会在两小时后(或更久)才联系你。简而言之,我们没有必要在支付后马上给用户分配配送员,而是在一定时间内(用户可接受)给用户分配到配送员就可以了。 也就是说我们可以把分配配送员的一系列操作滞后且异步化,但必须保证最终一定要分配到配送员。
小贴士:"马上"一词在这里指的是同步操作。至于是不是真的"马上",我也不太确定,也许只是因为人家用了另一种异步的解决方案,而且这个方案性能也非常棒。
实现选型:
我们已经推导出在这个业务场景下,可以通过最终一致性的理论解决大量同步操作所带来的困扰。那么我们应该通过什么手段去实践这个理论呢?
我的想法是通过消息队列去解决这个问题,已知目前比较流行的消息队列有3种:Kafka,RabbitMQ,RocketMQ。于是我稍微上网查了下资料,得出了比较简单的比较结果:
- Kafka:性能&吞吐量高,但没有消息重试机制,需要自己实现消息重试才能用于实现分布式事务(最终一致性)。
- RabbitMQ:可以通过消息重试+手动ack实现,但要保证消息的高可靠性需要付出昂贵的代价。
- RocketMQ:有官方实现的事务消息机制,同Kafka能在牺牲比较小的情况下保证消息高可靠性,但社区、文档实在不敢恭维(不信可以对比下官网)。
最终,由于我课设里面还计划用到延时消息,所以最终选了RocketMQ。RabbitMQ实现延时消息需要各种死信处理机制,实在不香。而Kafka要自己手动实现消息重试,编码量可能比较大,排错可能也比较难,时间有限,同样不香。
下面再附上一张RocketMQ事务消息的流程图(出自阿里官网)
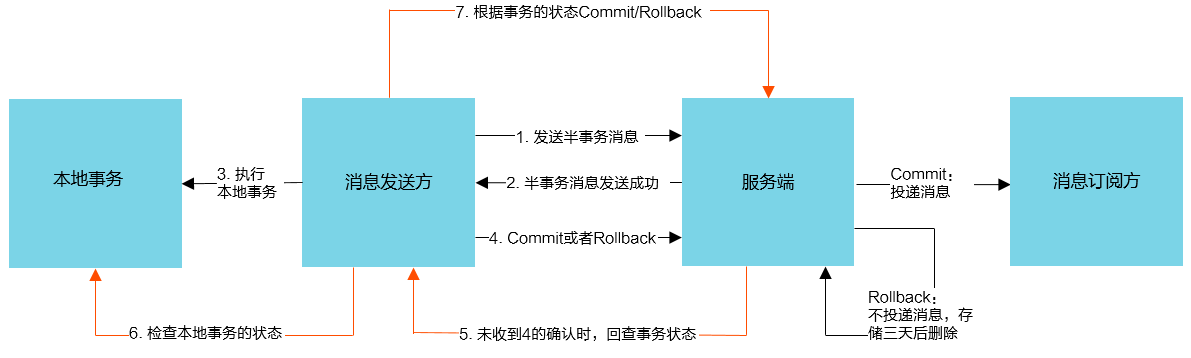
这里忍不住再吐糟一下RocketMQ的文档,信息量真的非常少,比较关键的地方甚至没有例图,整个文档几乎全是英文简介+一些代码,就连它事务消息的流程图我都不是从Apache官网找的,而是从阿里的文档里面找到的(开源版本贡献给Apache了)。
编写Lua脚本
Redis比较关键的流程可分为以下三点:
- zset 获取权重最高的配送员
- 空隙
- zset 减少上面获取到的配送员的权重
由于这里的设计是强保证,所以必须要保证当第一个请求进入【1】获取了一次权重最高的配送员后,如果此时有第二个请求试图进入【1】(此时第一个请求处于【2】),那么第二个请求必须等待第一个请求执行完【3】才能进入【1】,以免重复获取。为了保证这个过程的原子性,我采用了lua脚本。
Lua脚本如下:
--- 学校所属id
local school_id = KEYS[1]
--- 订单id
local order_id = KEYS[2]
--- 有效时间
local expire = ARGV[1]
--- 获取分数最高配送员
local res_courier_id = redis.call("ZREVRANGE", school_id, 0, 0)
--- 不为空再执行
if res_courier_id then
--- 扣除该配送员10分
if redis.call("ZINCRBY", school_id , "-10", res_courier_id[1]) then
--- 记录日志,记录成功再设置过期时间
if redis.call("set", order_id, res_courier_id[1]) then
--- 需要类型转换才能比较
if tonumber(expire) > 0 then
redis.call("expire", order_id, expire)
end
end
end
end
return res_courier_id
小贴士:Lua脚本是必须经过反复测试,确认没有死锁等致命问题的之后才使用的,但由于测试过程比较繁琐,我在这里就不一一赘述的,你只需要直到上面的脚本是经过一定测试的就可以了。
编写Java代码
先理一理DAO的代码思路:
// 假设配送员初始分数为10000
数据库业务操作函数(参数){
记录 = mysql在配送任务表中查询orderId的纪律
if(记录不存在){
String cid = redis/es 根据订单id查日志(日志的key/vlues形式为 订单id=配送员id)
if(cid不为空){
分配配送员id为cid的配送员配送此订单
// 删除日志(废除)
// 假设在此处删除日志: todo: 假如系统在这里宕机了,配送员9990分,那mysql事务回滚,mq回滚,因为日志删除,会进入下面的逻辑,配送员会被多扣分的
// 假设不在此处删除日志: todo 系统宕机,配送员9990分,mysql和mq都回滚,但因为日志依然存在,所以还是进入到此处逻辑,不影响分数一致性
}else{
// 使用lua实现确保一致性
redis取分数最高配送员,并减掉该配送员分数10,记录日志
mysql配送员配送记录
// 如果在在之后redis宕机了,代码还是会正常走下去,数据恢复只能靠aof了,默认是每秒保存,不管有没有持久化,都不影响正常业务主线
// 如果在此处是系统宕机了(redis没死),那么mysql事务也会回滚,mq也会重新发送,但因为有日志的存在,会进入上面的逻辑
// 如果系统和redis都死了,而redis持久化了,那么下次mq重投就会进入上面,如果没持久化,就重新进入此处,无论哪种情况,
// 都保证了分数的一致性(一般不会发生redis宕机,因为redis通常是第三方如阿里提供的远程服务)
}
}
}
再理一理MQ消费函数中文思路:
消息队列处理函数(参数){
数据库业务操作函数(orderId);
// 如果在此处宕机,mysql已提交,mq重投,但由于mysql记录已存在,相当于不执行,直接跳出来
删除日志;
// 如果在此处系统宕机,依旧是mysql已提交,mq重投,虽然删除日志的操作重复了,但不影响一致性
// 如果redis挂了没持久化,也是日志没被删除而已,ttl时间过后自动删除,不会影响正常业务
// 如果系统和redis都挂了,mysql已提交,mq重投,无论redis有没有持久化,也只是影响到日志而已,跟上一个如果相似,不影响正常业务
}
最终变成如下两个函数:
/**
* 考虑到MQ的其它特性,再加了点代码。
* @param orderId 订单id
* @param type 执行类型 first-支付之后分配 re-手动重新分配
*/
@Override
@Transactional(propagation = Propagation.REQUIRED, rollbackFor = Exception.class)
public void distributionCourier(String orderId, String type) {
// 查询对应订单id且配送员id为""的订单记录
OrderInfo orderInfo = orderInfoMapper.selectOne(
new QueryWrapper<OrderInfo>().
eq("id", orderId).
eq("courier_id", ""));
orderInfo.setUpdateDate(null);
// 一般情况下,如果是因网络波动重复发送的消息,就会直接跳过下面的if了,因为重复发送一般是很久没有收到回答信息
int updateCount = 0;
if (!ObjectUtils.isEmpty(orderInfo)){
// 查询 redis 日志
String logKey = RedisConfig.ORDER_COURIER_DATA + "::" + orderId;
String courierId = redisService.get(logKey);
if (!StringUtils.isEmpty(courierId)){
orderInfo.setCourierId(courierId);
// 只有支付后分配才将状态改为等待揽收
if ("first".equals(type)){
orderInfo.setOrderStatus(OrderStatusEnum.WAIT_PICK_UP);
}
updateCount = orderInfoMapper.update(orderInfo, new QueryWrapper<OrderInfo>()
.eq("id", orderId).eq("courier_id", ""));
}else {
// 查询下单者的学校id(远程调用)
SysUser user = ucenterFeignClient.getById(orderInfo.getUserId());
// redis 选取该学校分数最高的配送员,并减掉该配送员分数10,记录日志
String key = RedisConfig.COURIER_WEIGHT_DATA + "::" + user.getSchoolId();
List<String> keys = Arrays.asList(key, logKey);
courierId = stringRedisTemplate.execute(redisScript, keys, String.valueOf(RedisConfig.DISTRIBUTION_LOG_TIME_OUT));
if (StringUtils.isEmpty(courierId)){
ExceptionCast.cast(CommonCode.COURIER_NOT_EXIST);
}
orderInfo.setCourierId(courierId);
if ("first".equals(type)){
orderInfo.setOrderStatus(OrderStatusEnum.WAIT_PICK_UP);
}
updateCount = orderInfoMapper.update(orderInfo, new QueryWrapper<OrderInfo>()
.eq("id", orderId).eq("courier_id", ""));
}
}
if (updateCount == 0){
log.warn("【分配配送员业务】可能由于网络波动,消息被重复消费,订单号:{}", orderId);
}
}
}
/**
* @author cwj
* 延时消息取消订单单和关闭支付
*/
@Service
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
@RocketMQMessageListener(consumerGroup = RocketmqConfig.DISTRIBUTION_COURIER_GROUP, topic = RocketmqConfig.DISTRIBUTION_COURIER_TOPIC)
@Slf4j
public class DistributionCourierConsumer implements RocketMQListener<String> {
private final DistributionCourierService distributionCourierService;
private final RedisService redisService;
@Override
public void onMessage(String orderIdAndType) {
String[] values = orderIdAndType.split("@@");
String orderId = values[0];
String type = values[1];
// 分配配送员业务
distributionCourierService.distributionCourier(orderId, type);
// 删除redis日志 (可以不删,但要完善权重自动/手动校准机制)
String logKey = RedisConfig.ORDER_COURIER_DATA + "::" + orderId;
redisService.remove(logKey);
}
}
再补上Lua初始化:
@Configuration
public class LuaConfiguration {
@Bean
public DefaultRedisScript<String> redisScript() {
DefaultRedisScript<String> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/distribution.lua")));
redisScript.setResultType(String.class);
return redisScript;
}
}
小结/扩展
Lua脚本注意点:
Lua脚本虽然能保证原子性,但因为redis是单线程io多路复用模型, 所以在执行Lua的时候,会"阻塞"住当前执行Lua脚本的redis节点的所有其它读写请求,直到当前运行的Lua脚本执行完成。
注意!!!
上面的的"阻塞"是指一个正在执行的Lua线程处于阻塞状态,并不是指当一个Lua正在运行时再运行其它命令会阻塞,如果上一个Lua还在运行,那么再执行其它任何读写命令都会出现(error) BUSY Redis is busy running a script. You can only call SCRIPT KILL or SHUTDOWN NOSAVE.
如果是主从模式,主节点正在运行一个Lua脚本,从节点依然可读但不可写。
这也就意味着,lua脚本必须不允许出现死锁、且不能是执行时间长的脚本(如果是执行时间比较长的脚本,应该限流+完善容错重试机制)。
还有就是redis的lua脚本特性所衍生出来的长连接/任务超时问题:
如果lua脚本因某种原因导致长时间阻塞,那么就有可能导致分配配送员消息消费失败重试/长连接导致连接丢失,然后重试的消息不断重试还是失败,最终消息积压爆表,可能导致服务雪崩/长连接过多导致新用户无法再连接。
对于长连接的解决我自然是用RocketMQ解决,毕竟假设在海量数据的情况下,完整的插入事务流程肯定比发送一条事务消息更耗时。
至于失败消息积压方面解决的方案就有很多,包括sentinel限流、rocketmq限制消费的线程池等。
软保证
上面的强保证,主要体现在我们使用了Lua脚本保证了操作原子性,也就是保证了在一定并发下,绝对不会出现重复获取同一权重且同一配送员的情况。
但是这种强保证,无疑给我们带来了很大限制(主要指Lua脚本的限制)。
我们可以再仔细想一想,配送员的公平性是不是一定要强保证呢?因为系统是长久运行的,就算在某一段时间出现了高并发,并且由于网络波动这几个并发请求都获取到了同一个配送员,但从结果来看,这位被重复获取的配送员,该扣的权重还是被扣了。
那么在之后的一段时间内,这位被重复获取的配送员【1】,权重应该是垫底的,且其它配送员就算再扣几次权重,排名也应该还是比配送员【1】高。
也就是我们从系统会长期运行的角度看,就算没有强保证,我们依然能保证配送员的分配是接近于平均的,这种观点有点类似于"最终一致性",我把它称为"软保证"。
使用软保证虽然会破坏短期内的平衡性,但它能保证长期内平衡不会破坏的很离谱,且不再受Lua的限制,提高系统并发。当然,前提是业务能接受短期的不平衡。
参考资料: