前言
观前提示:本文并不会对锁机制、日志机制、缓存池机制等额外机制进行讨论,一是因为我觉得这篇文章没有这些会更便于理解,而是把这些都塞到一篇里实在太肿了,其它机制的博客敬请期待吧~
例子sql:UPDATE demo SET col='你好' where id=1;
(col是varchar类型,表只有这两字段,col原值也是两个中字)
当我还年少无知的时候,曾一度认为MYSQL的update语句执行流程是这个样子的:
- 根据聚簇索引快速定位到该条记录的位置
- 将该条记录的col值更改为"你好"
- 更新完成
那么这种想方法到底对不对呢?
答案:对,但是不全对。
解释
实际上,MYSQL的update语句执行流程并没有想象中的那么简单。
这里简单把update针对不同情况的处理方案列举出来:
- 不更新主键
- 就地更新
- 删除再插入
- 更新主键
- 先delete再insert
注意!"删除再插入"和"先delete再insert"是两个不同的概念。
之后会给delete和insert单独写博客,简单介绍一下流程,对于锁问题不在此系列作过多解释,有空会单独开出关于锁问题有关的篇章。
就地更新
就地更新的前提:
- 不更新主键。
- 更新前的列和更新后的列所占用的存储空间一样大。
请重点关注"存储空间一样大"
这也是为什么我特地要说col的字段类型是varchar,而不是char和varchar都可以。
关于varchar和char的区别大家可自行百度,在这里不在赘述。
在这里你只需知道char占用的长度和空间都是固定的就可以了。
其实就地更新的流程很好理解,就是我们在前言中所说的流程,直接修改原来的记录值,更新统计信息,不会有更多特别的操作。
但对于:UPDATE demo SET col='你好啊' WHERE id=2;
情况可就不一样了,因为更新前后列占用的存储空间不一样的,也就是下面要讲的"删除再插入"。
删除再插入
删除再插入前提:
- 不更新主键。
- 更新前的列和更新后的列所占用的存储空间不同。
是不是感到有些意外?但事实就是如此。
除此之外,如果你熟悉delete的流程,那你可能会认为这个"删除再插入"是指先经过 delete_mask 的中间状态,然后再被 purge 的回收,之后再是insert流程balabala~的。
但是实际上,此处的"删除再插入"并没有那么复杂,就是简单粗暴的将记录原地删除并回收至垃圾链表,之后再重新插入一条新的记录,并更新统计信息。(此过程也是原子性操作,也就是不会出现删除后查询为空的情况,或者删除后断电导致记录消失的情况)
接下来就是最后一种情况了。
先delete再insert
触发这种情况的前提:
- 更新主键
没错,触发这种情况并没有什么很复杂的条件,只要更新主键,就会触发。
比如: UPDATE demo SET id=2 where id=1;
至于delete和insert的简单流程,这里就不细说了,后期会单独开篇章讲(与锁无关,与锁有关的也会单独开篇章)。
那么为什么在更新主键的情况下,就要走一遍delete和insert的流程呢?
给个小提示= =,和聚簇索引的数据保持有序有关~
我相信熟悉MYSQL底层B+数存储结构的小伙伴已经知道答案了。
其实就是为了让主键索引列保持有序。
借用一下小册子中的一张图。
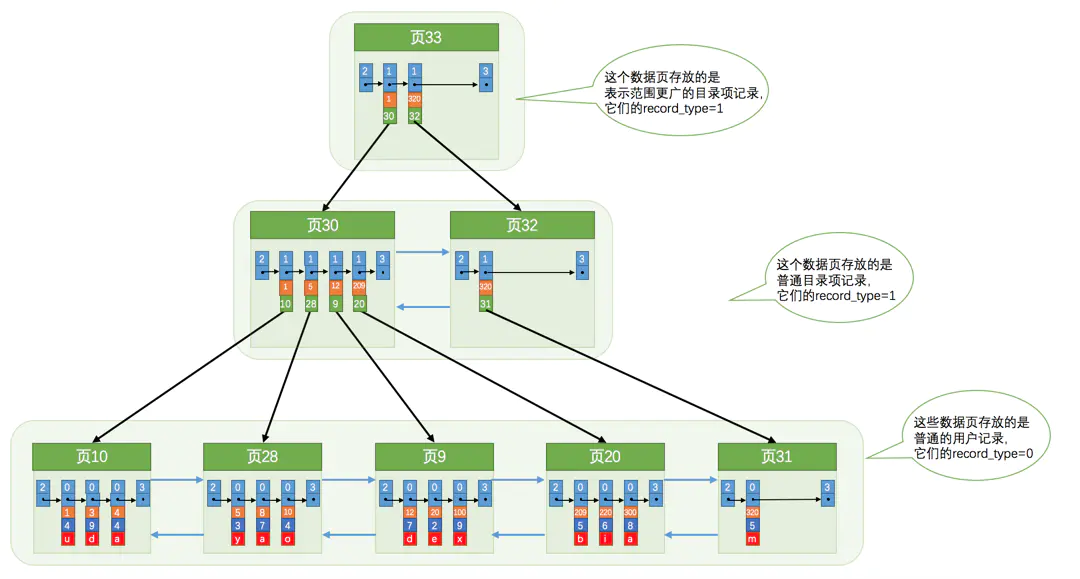
其中橙色单元格表示的就是主键,可以看到聚簇索引(二级索引)的数据都是根据主键(索引列)排序的。
回到上面的问题,如果主键更新了,数据只是就地更新或者就地删除再插入,那么整颗索引树可能就废掉了~,因为如果数据是有序的,我们很容易就想到二分查找,而如果数据都变无序了,二分查找就没有意义了。
扩展
上面的内容其实都是基于聚簇索引(主键)树来讲的。
对于二级索引并没有细说,但是根据上面的讨论的结果,也很容易推敲出二级索引的变化流程,因为二级索引也是b+树,数据也是有序的,只是以索引字段排序而已,所以关于二级索引的更新情况这里就略了。相信如果真的看懂了上面的,也不难推测得出结果。