前言
如果被问起Redis的LRU机制,相信绝大多数人都能清楚的讲出算法的思想,牛逼起来的人甚至能用自己熟悉的语言去手撕这个算法。
而且说起LRU,绝大部分Java程序员的第一反应可能都是Redis。但其实除了常用的Redis,我们的MYSQL也有LRU,因为MYSQL为了提高查询速度也设置了缓冲池(Buffer Poll)作为数据缓存。
那既然MYSQL同Redis一样都使用到了缓存,且内存大小都有限,那自然是要想办法提高缓存命中率,所以不难想象MYSQL也有自己的LRU实现方案。
缓存命中率:假设我们一共访问了n次页,那么被访问的页已经在缓存中的次数除以n就是所谓的缓存命中率。(摘自掘金小册)
简单的LRU
简单的LRU其实就是在内存不足时,淘汰链表中最少被使用的数据,保留热点数据。
我自己画了张简图描述一下这个过程:
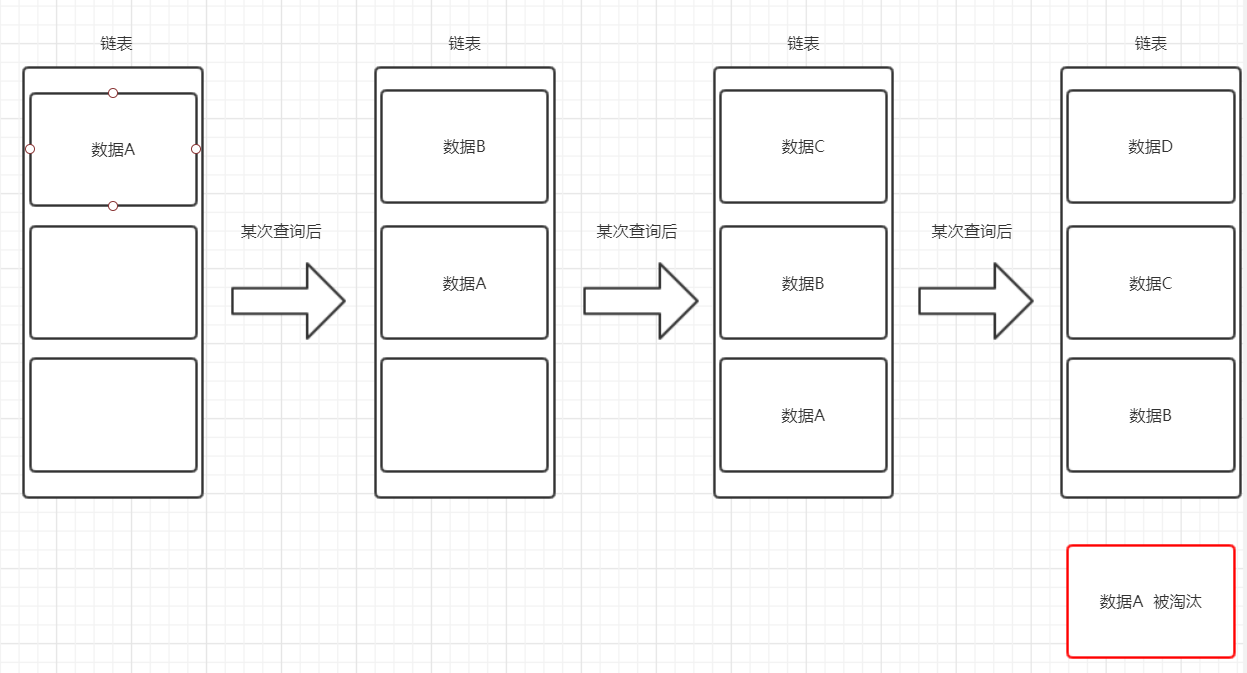
简单LRU的不足
如果将上述的简单LRU应用到Redis或者其它内存淘汰机制,大可能及格。
但是要运用到MYSQL行不行呢?答案是不行,这和MYSQL一些机制有关。
下面主要针对两点进行分析:
- 磁盘预读
- 全表扫描
磁盘预读:
当我们在某个区中查询大量数据页的时候,MYSQL为了提高响应的速度,为我们提供了一种贴心的服务,即磁盘预读。
区(英文:extent)的简单概念:连续的64的页(页大小16Kb)就是一个区,区的目的主要是为了让这64个页存储的物理地址相邻,减少随机I/O。在区的上层还有个"段"的概念,如果想了解,请自行查阅资料吧~本文就不扯远了。
- 随机预读:如果一个区中有13个连续的页被Buffer Pool缓存了,且这13个页都位于young区的前1/4(下面会提到),那么无论这十三个页是不是被顺序读进Buffer Pool的,都会触发随机预读把数据读进Buffer Pool,且预读是异步的。
- 线性预读:如果一个区中被顺序访问的页面达到系统设置的阈值(默认:56),那么就会触发线性预读,异步读取剩余页的所有数据到Buffer Pool中。
显然,如果我们按照简单LRU的思路实现内存淘汰,可能会导致部分真正的热点数据被预读的数据淘汰掉,而预读的数据又不一定被使用到,之后缓存命中率就会下降。
全表扫描:
对于线上业务我们绝大部分情况下都不会使用到全表扫描,但对于某些比较"憨憨"的场景,我们不得不使用,就如:数据库备份。
全表扫描的过程其实也会不断的把数据页加载到Buffer Pool中,而如果用简单LRU实现内存淘汰,也会造成"劣币驱良币"。比如数据库备份时,就会把缓存中原有的热点数据淘汰,最终降低缓存命中率。
MYSQL的LRU实现
为了不让全表扫描和磁盘预读"污染"热点数据,MYSQL对简单的LRU进行了一番改造,具体看下图(图片出自MYSQL5.7/8官方文档):

从图中我们可以获取到的重要信息:
- MYSQL将LRU链表分为了Young(New)区,和Old区。
- 当数据首次加载时,会先被加载到Old区的头部。
那么这两个重要信息有什么用呢?我仔细阅读官方手册和参考书籍得到了以下答案(原文较多,我就不贴了):
- MYSQL首次读取数据页时,会将数据页放在Old区域的头部,如果该数据页在之后再被用到,那么它才有机会晋升到Young区成为热点数据。
- 针对全表扫描和磁盘预读,它们查询时的得到的数据页,插入点都在Old的头部,不会影响Young区的热点数据,且之后如果这部分数据没有被用到,就会被新数据淘汰掉。
根据以上答案,MYSQL就很好的解决了磁盘预读和全表扫描给简单LRU链表带来的"污染"。
进一步优化
如果仅仅是针对磁盘预读和全表扫描,上面的LRU策略已经算及格了,但MYSQL的设计者们怎么会止步如此呢?
仔细想想,假如我们的缓存命中率很高,或者比较极端,到达了100%。那么针对Young区的数据,可能产生如下图的流程:
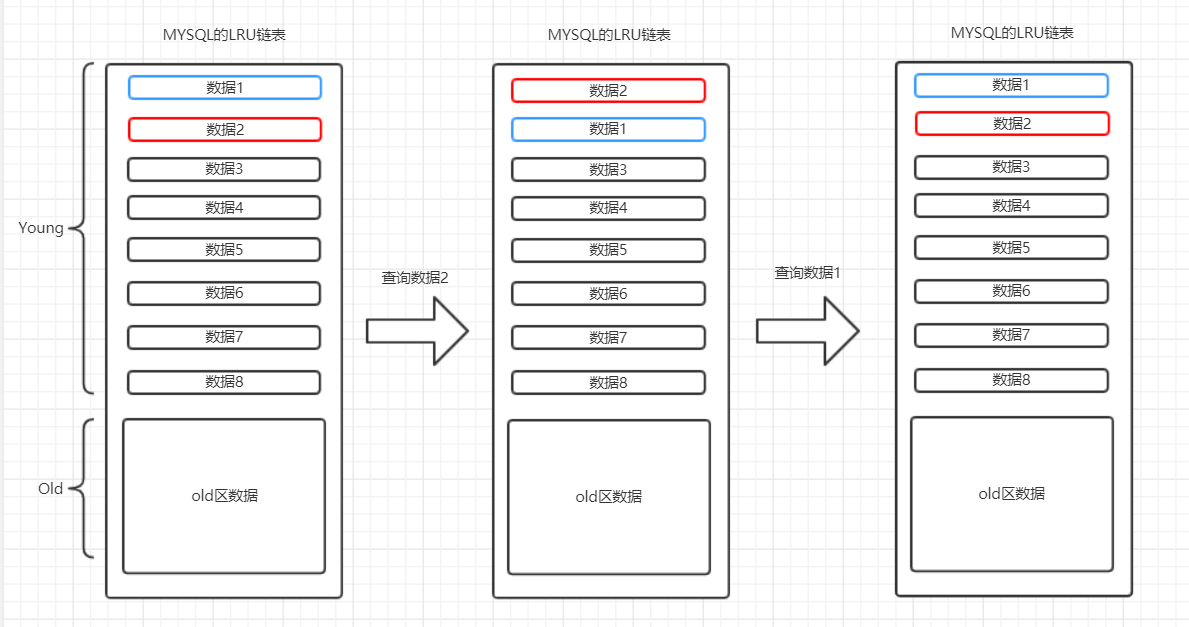
可以看到Young区域的数据再不断的交换位置,因为根据我们上面的理论,每次被查询到的数据都要放到LRU链表的头部,但这种做法在MYSQL的设计者眼中是浪费内存、浪费CPU的体现。
于是,MYSQL的设计者决定,对于Young区前1/4的数据,即使被用到了,也不动。先前的流程变成了下面的样子:
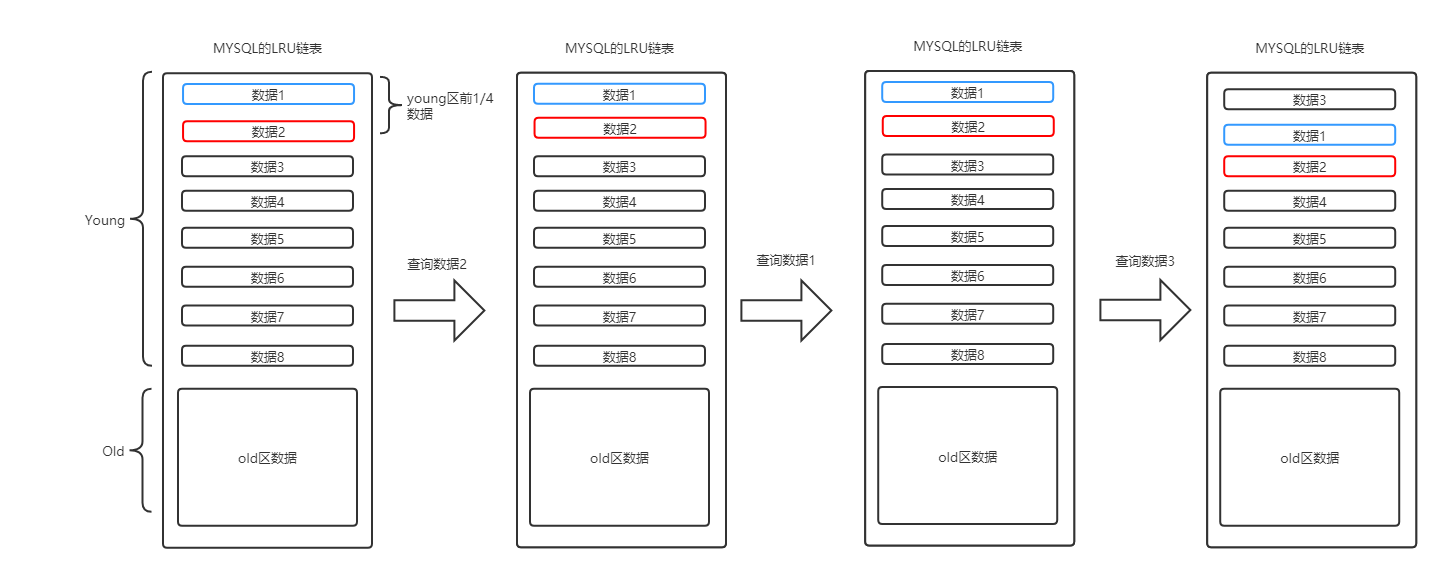
这样,就可以在不影响缓存命中率的前提下,减少内存、CPU的资源占用了。
小贴士:优化这一段主要摘自掘金小册+自己画的图(便于理解),我在MYSQL的文档和一些博客里面貌似没有找到相关内容,如果日后有更多资料的话会补上这一块的。或者有能力的同学可以分析下源码是不是这么回事,分析到的话给我个传送门,我会为你点赞~
小结
本文讲了很多关于MYSQL实现LRU的一些思路,但我们不能忘了初心,那就是这些设计思路都是为了提高缓存命中率、减少内存&CPU的负担而存在的。
参考资料: